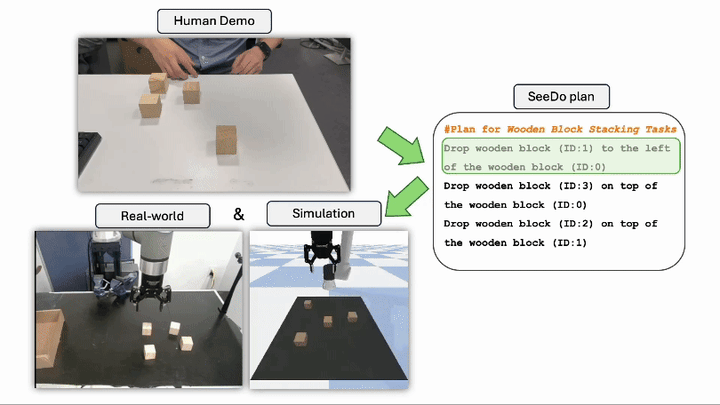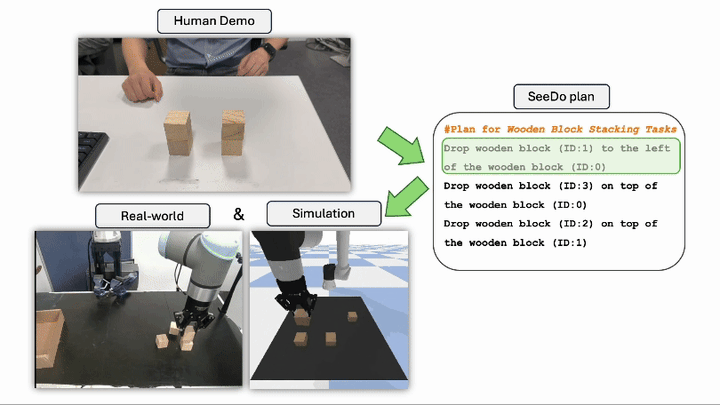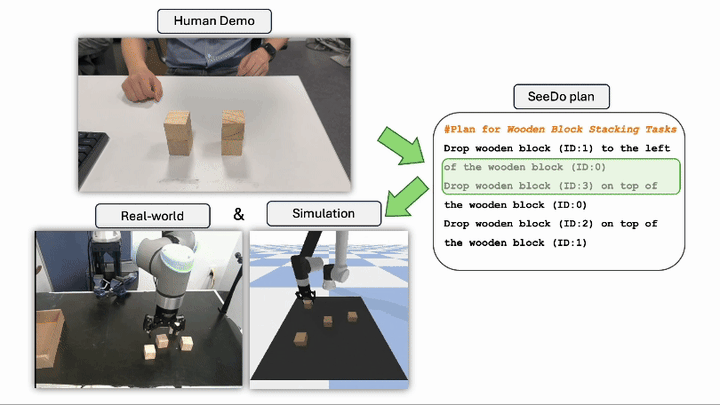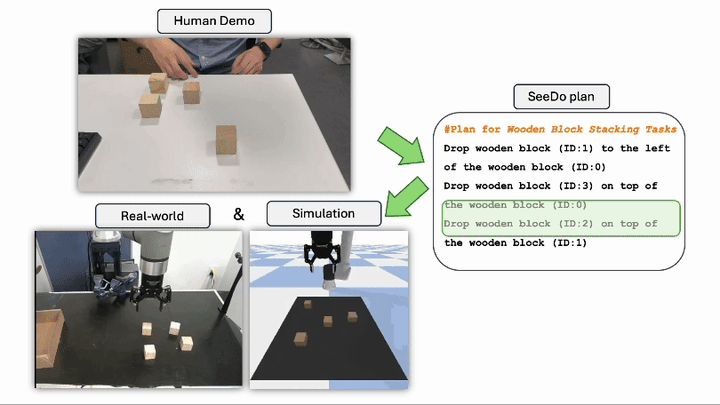
VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model Beichen Wang*, Juexiao Zhang*, Shuwen Dong, Irving Fang, Chen Feng Go to Project Site PDF Code Project 1 2 5 6 Reasoning Chen Feng Associate Professor at NYU