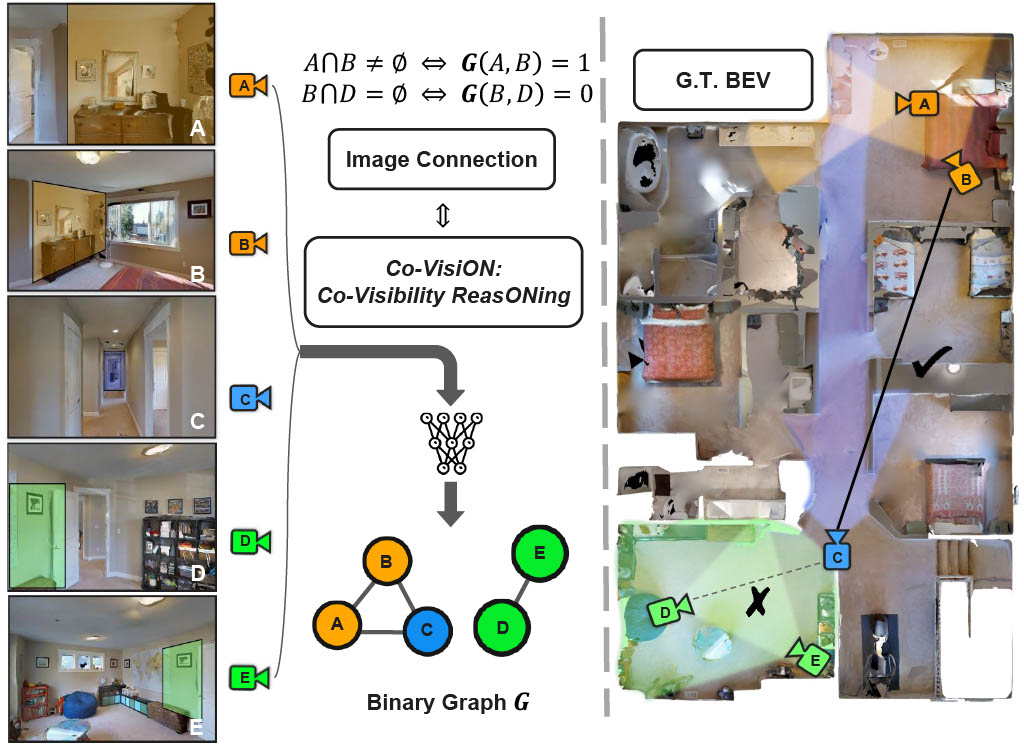
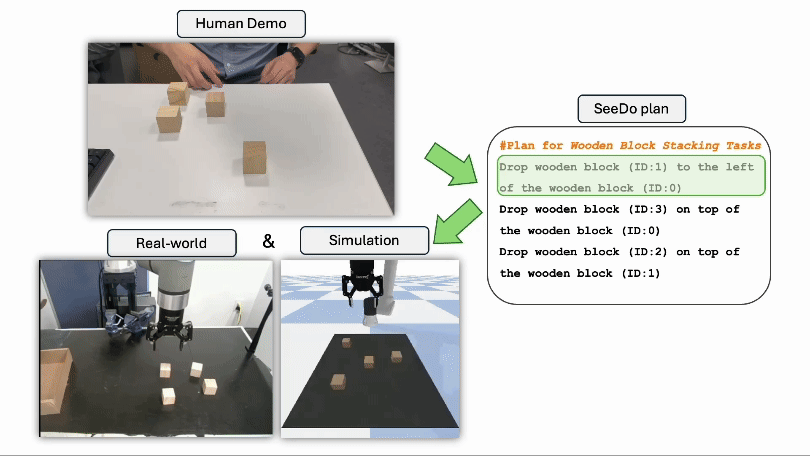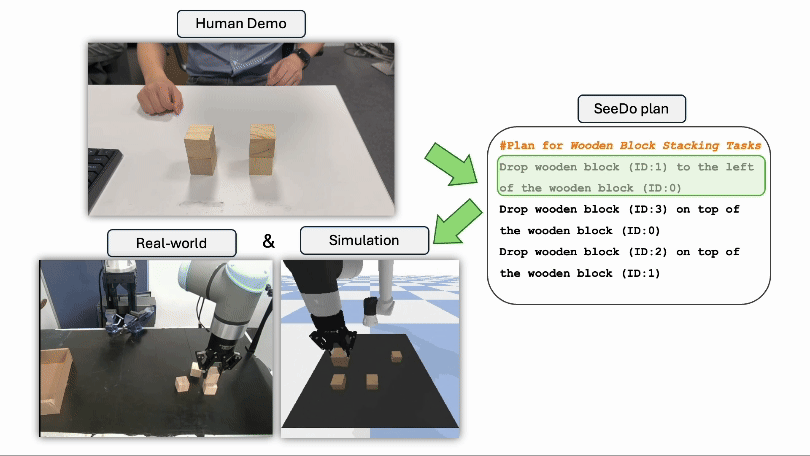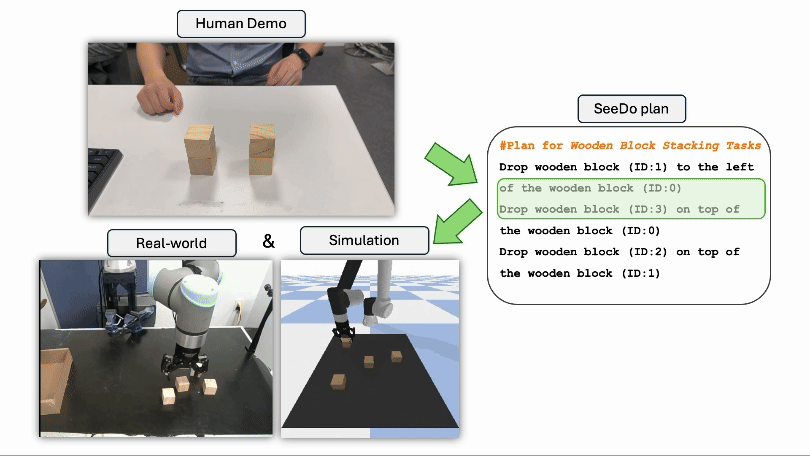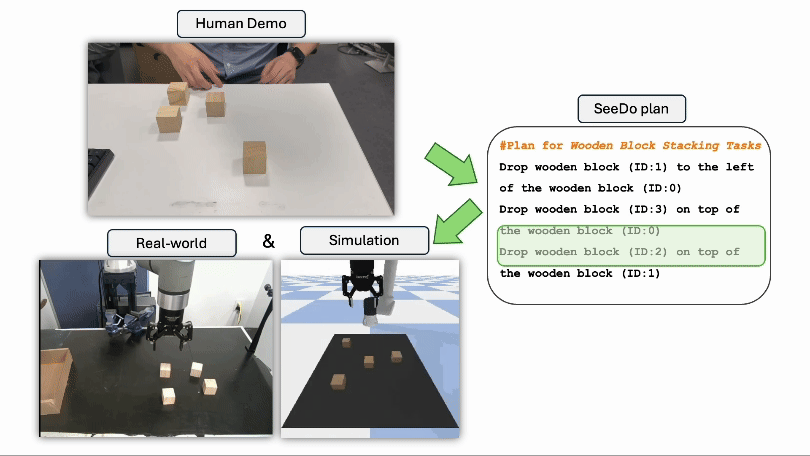
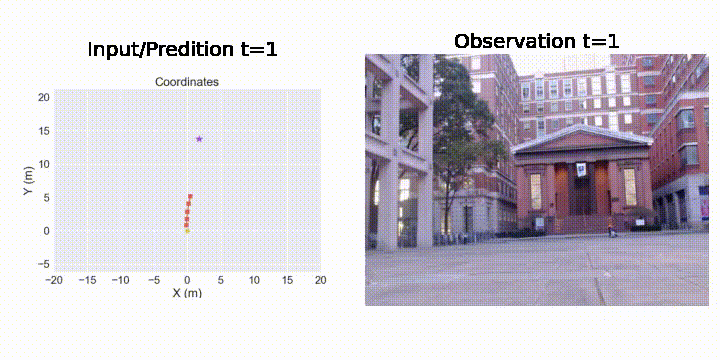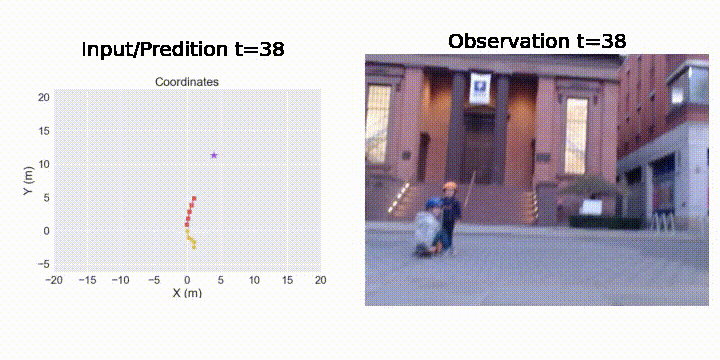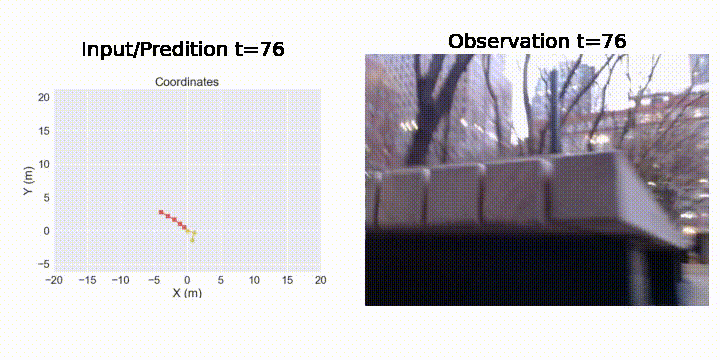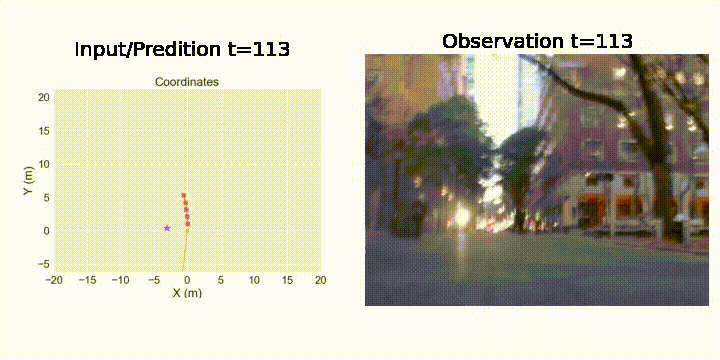
Sihang Li
Siqi (Kevin) Tan
Bowen Chang
Jing Zhang
Chen Feng
Yiming Li
Xiangyu Han
Zhen Jia
Boyi Li
Yan Wang
Boris Ivanovic
Yurong You
Lingjie Liu
Yue Wang
Marco Pavone
Zeyu Jiang
Grace Chen
Chenyang Xu
Xue Wang
Irving Fang
Kristof Zyskowski
Shannon P. McPherron
Radu Iovita
Chao Chen
Nobel Dang
Juexiao Zhang
Wenkai Sun
Pengfei Zheng
Xuhang He
Yimeng Ye
Taarun Srinivas
Beichen Wang
Shuwen Dong
Xinhao Liu
Jintong Li
Yicheng Jiang
Niranjan Sujay
Zhicheng Yang
John Abanes
Gao Zhu
Haorui Song
Xinran Tang
Yuzhong Chen
Yifan Wang
Jianghan Zhang
Qiushi Zhang
Jiali Xu
Xibo He
Weibo Gao
Hao Su
Zhiheng Li
Nuo Chen
Moonjun Gong
Zonglin Lyu
Zehong Wang
Peili Jiang
Suozhi Huang