
A robot's ability to anticipate the 3D action target location of a hand's movement from egocentric videos can greatly improve safety and efficiency in human-robot interaction (HRI). While previous research predominantly focused on semantic action classification or 2D target region prediction, we argue that predicting the action target's 3D coordinate could pave the way for more versatile downstream robotics tasks, especially given the increasing prevalence of headset devices. This study substantially expands EgoPAT3D, the sole dataset dedicated to egocentric 3D action target prediction. We augment both its size and diversity, enhancing its potential for generalization. Moreover, we substantially enhance the baseline algorithm by introducing a large pre-trained model and human prior knowledge. Remarkably, our novel algorithm can now achieve superior prediction outcomes using solely RGB images, eliminating the previous need for 3D point clouds and IMU input. Furthermore, we deploy our enhanced baseline algorithm on a real-world robotic platform to illustrate its practical utility in a straightforward HRI task. This demonstration underscores the real-world applicability of our advancements and may inspire more HRI use cases involving egocentric vision.
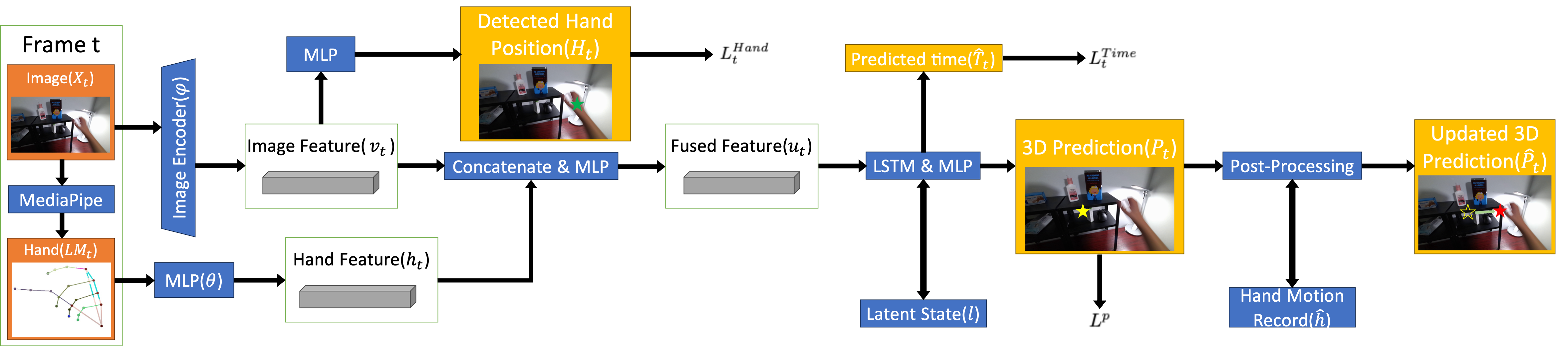
We employ ConvNeXt_Tiny (denoted by ψ) to extract visual feature vt = ψ(Xt) from each RGB frame. Hand landmarks {LM1t, LM2t ... LM21t} are firstly extracted by the Hand API from Google's MediaPipe. If no hand detected, then all landmarks are set to be 0. A multi-layer perceptron (MLP) denoted by φ is then used to encode hand landmarks to features ht = φ(LM21stackt). After the feature encodings, the two features were concatenated and fed into another MLP to obtain the fused feature ut = MLP(cat(vt,ht)) for a single frame.
We use a 2-layer LSTM to process the fused feature. The steps to handle LSTM outputs are similar to the original EgoPAT3D baseline. We divide a 3D space into grids of dimension 1024×1024×1024 and aim to generate a confidence score for each grid. We used three separate MLPs to process the output of the LSTM and obtain the confidence scores in three dimensions. For example, without loss of generality, for dimension x at frame t, let g ∈ ℝ1024 denote all the grids in the x-dimension, where we normalize the coordinates of each grid to be in [-1, 1]. The score vector sxt ∈ ℝ1024 is computed by sxt = MLPX(LSTM(ut, lt-1)), where lt-1 is the learned hidden representation and l0 is set to be 0. A binary mask mtx ∈ ℝ1024 is used to remove the value for all the grids where the confidence is less than a threshold γ. Let sxt[i], mxt[i] denote the score and mask for the i-th grid, we have that:
The masked score is then calculated by ŝxt = mxt ⊙ sxt, where ⊙ denotes the element-wise dot product. Then, we can get the estimated target position value for dimension x at frame t as:
We conduct post-processing for each result produced by the LSTM to incorporate human prior knowledge. For each frame t, we choose the coordinate of the landmark that marks the end of the index finger to be the 2D hand position Ĥt. The predicted 3D target position Pt (in meter) was transformed into 2D position ĤPt in pixel values with the help of camera intrinsic parameter K and image resolution (4K in our case). We ignore the depth information in this transformation. We calculate the hand position offset between each frame by ĥt = ||Ĥt - Ĥt-1||2 and keep track of the max historical hand position offset Ĝt = max(ĥt) for i < t. The final 2D position is calculated as ĜPt = ĤPt*(ĥt/Ĝt) + Ĥt*(1-ĥt/Ĝt). The 2D result is then transformed back to a 3D position ĥat{Pt} with the pre-transformed depth, again with camera intrinsic parameter K and image resolution, to serve as the final prediction.
@INPROCEEDINGS{Fang2024,
author={Fang, Irving and Chen, Yuzhong and Wang, Yifan and Zhang, Jianghan and Zhang, Qiushi and Xu, Jiali and He, Xibo and Gao, Weibo and Su, Hao and Li, Yiming and Feng, Chen},
booktitle={2024 IEEE International Conference on Robotics and Automation (ICRA)},
title={EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot Interaction},
year={2024},
volume={},
number={},
pages={3036-3043},
doi={10.1109/ICRA57147.2024.10610283}}