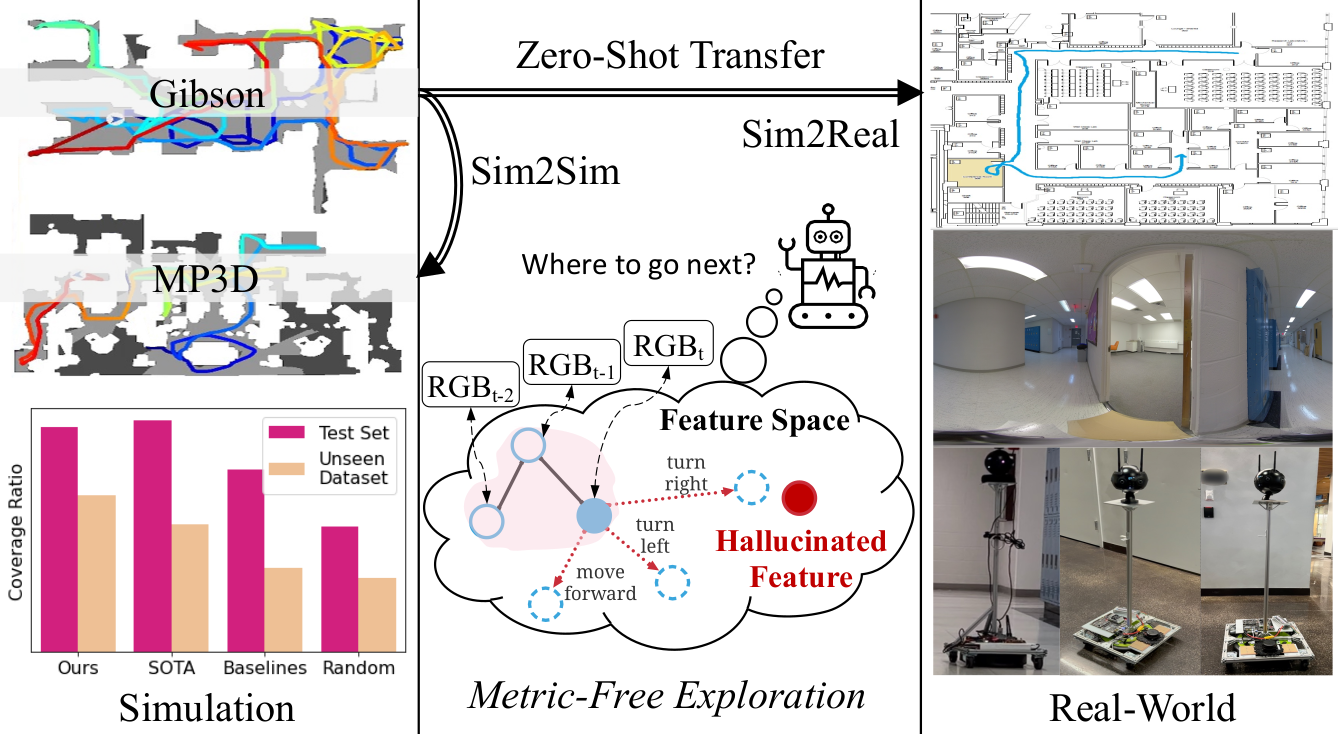
We propose DeepExplorer, a simple and lightweight metric-free exploration method for topological mapping of unknown environments. It performs Task And Motion Planning (TAMP) entirely in image feature space.
The two planners are jointly trained via deeply-supervised imitation learning from expert demonstrations. During exploration, we iteratively call the two planners to predict the next action, and the topological map is built by constantly appending the latest image observation and action to the map and using visual place recognition (VPR) for loop closing.
The resulting topological map efficiently represents an environment's connectivity and traversability, so it can be used for tasks such as visual navigation. We show DeepExplorer's exploration efficiency and strong sim2sim generalization capability on large-scale simulation datasets like Gibson and MP3D. Its effectiveness is further validated via the image-goal navigation performance on the resulting topological map. We further show its strong zero-shot sim2real generalization capability in real-world experiments.
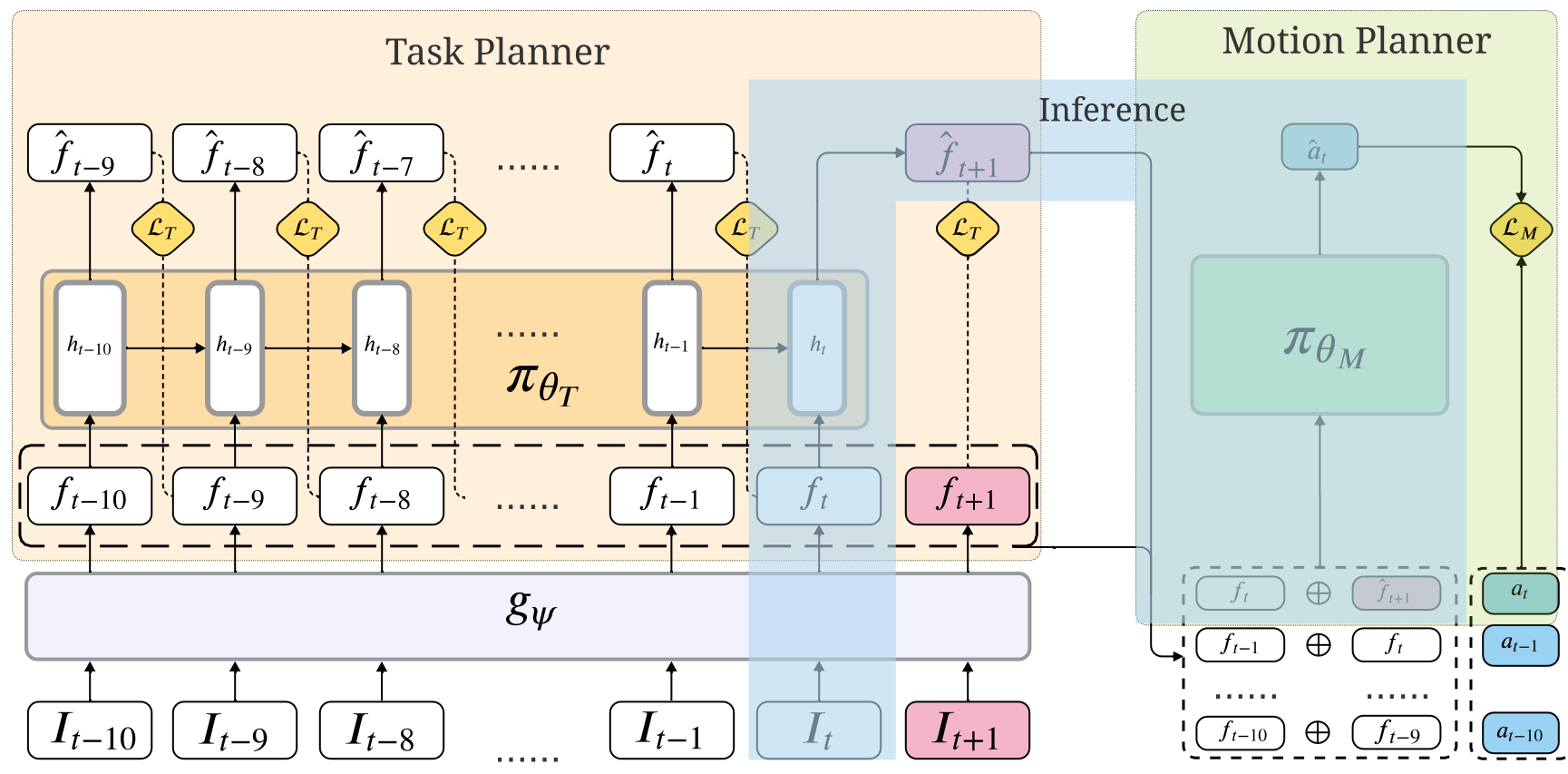
The feature extractor gψ takes image It as input and generates the corresponding feature vector ft. TaskPlanner πθT is a recurrent neural network (RNN) consuming a sequence of features {ft−10 , · · · , ft } to hallucinate the next best feature to visit f̂t+1 . MotionPlanner πθM consumes the concatenation of ft and f̂t+1 and generates the action to move the agent towards the hallucinated feature. During training, we supervise all the intermediate outputs including the intermediate hallucinated features { f̂t−9 , · · · , f̂t } and the intermediate actions {ât−10 , · · · , ât−1 }, in addition to the final output f̂t+1 and ât. During inference, current observation It is firstly encoded and fed into πθT to hallucinate f̂t+1 , and then f̂t+1 combined with the ft is fed into πθM for motion planning. LT is L2 loss and LM is cross entropy loss (the subscripts T and M denote Task and Motion respectively). ht denotes the hidden state of RNN.
(a) Gibson dataset
(b) MP3D dataset
(c) Real-World indoor dataset
We employ three datasets for a comprehensive evaluation: (1) Gibson dataset, (2) MatterPort3D (MP3D) dataset, and (3) Real-World indoor dataset.
@INPROCEEDINGS{He-RSS-23,
AUTHOR = {Yuhang He AND Irving Fang AND Yiming Li AND Rushi Bhavesh Shah
AND Chen Feng},
TITLE = {{Metric-Free Exploration for Topological Mapping by Task and
Motion Imitation in Feature Space}},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2023},
ADDRESS = {Daegu, Republic of Korea},
MONTH = {July},
DOI = {10.15607/RSS.2023.XIX.099}
}