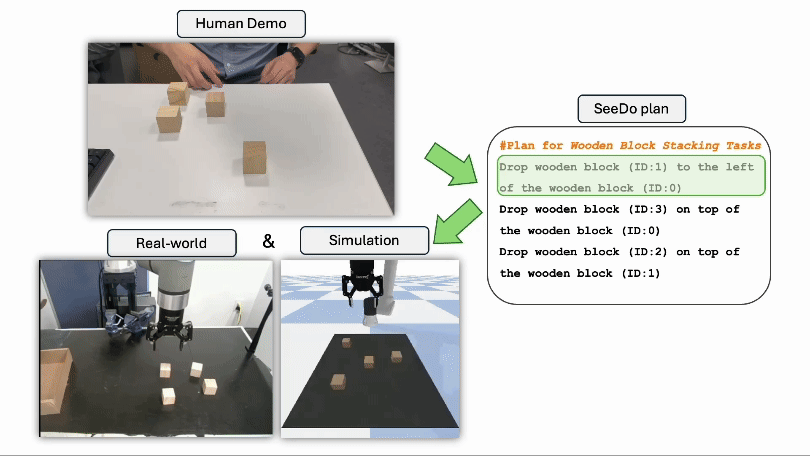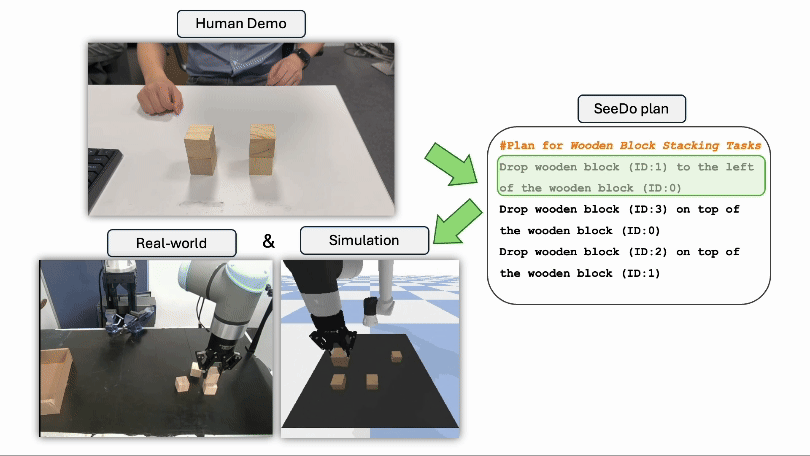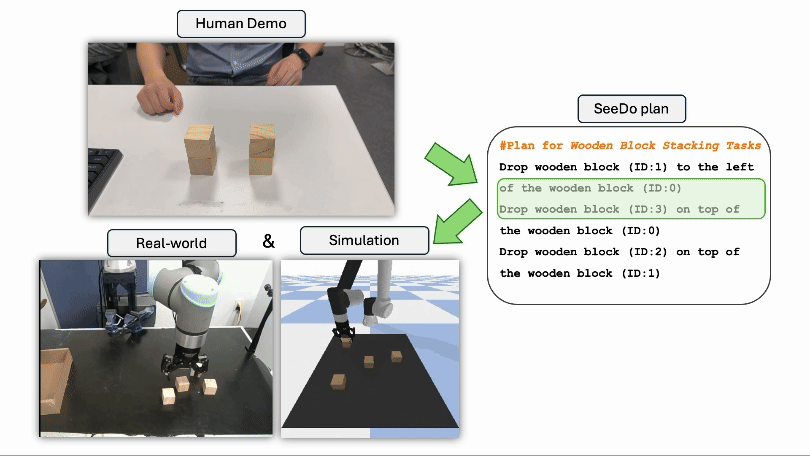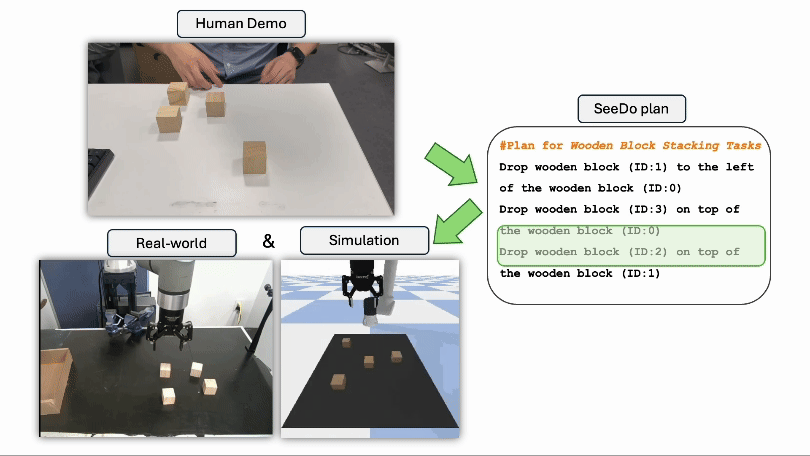
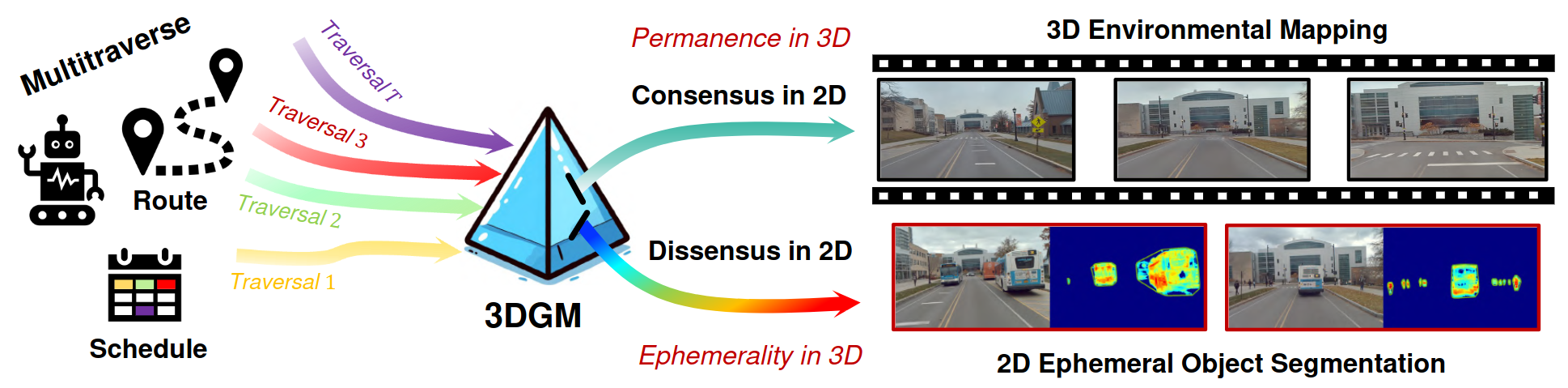
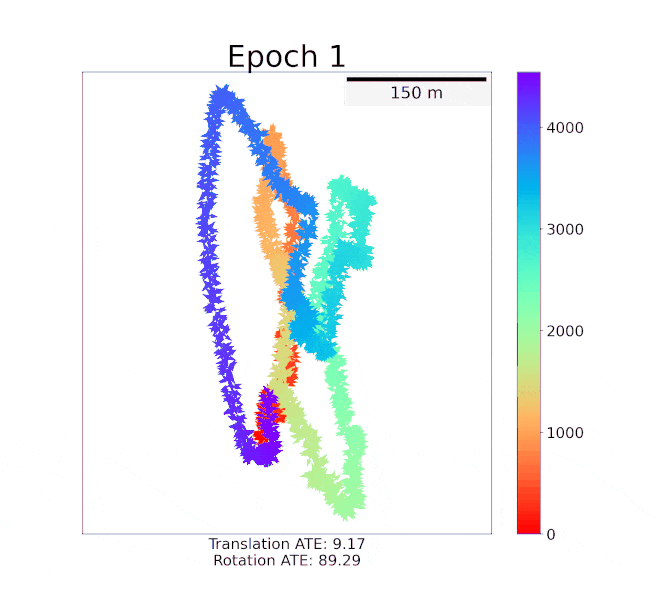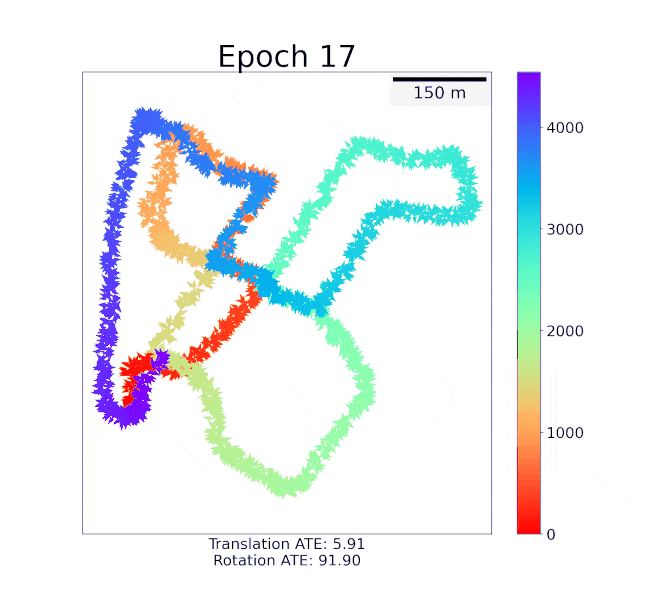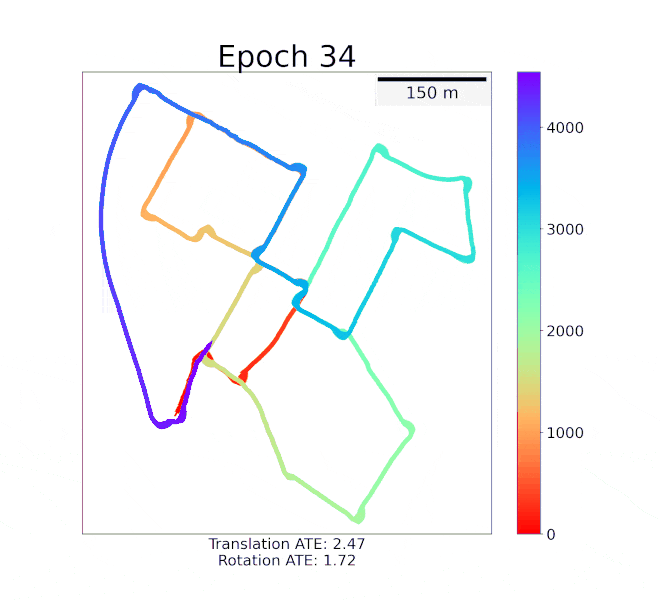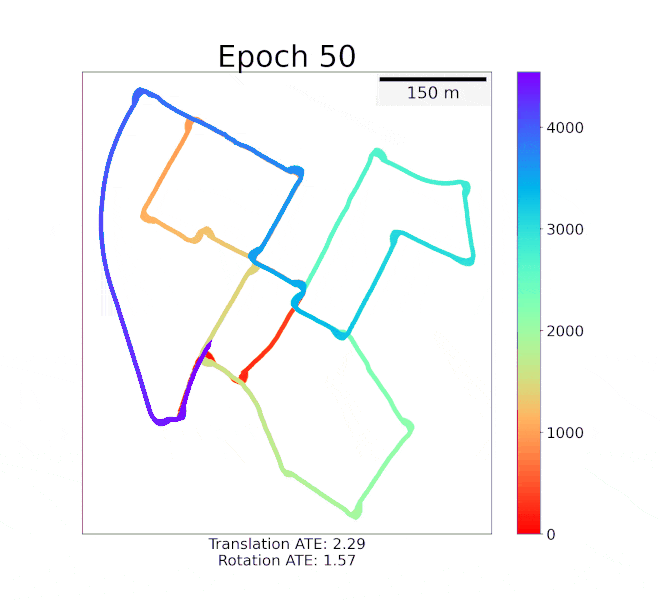
Sihang Li
Siqi (Kevin) Tan
Bowen Chang
Jing Zhang
Chen Feng
Yiming Li
Beichen Wang
Juexiao Zhang
Shuwen Dong
Irving Fang
Zehong Wang
Yue Wang
Zhiding Yu
Zan Gojcic
Marco Pavone
Jose M. Alvarez
Gao Zhu
Xinhao Liu
Haorui Song
Xinran Tang
Chao Chen
Li Ding
Xuchu Xu
Ruoyu Wang
Diwei Sheng
Yuxiang Chai
Xinru Li
Jianzhe Lin
Claudio Silva
John-Ross Rizzo
Siheng Chen
Baoan Liu
Carlos Vallespi-Gonzalez
Carl Wellington
Lichao Xu
Vineet R Kamat
Carol C Menassa