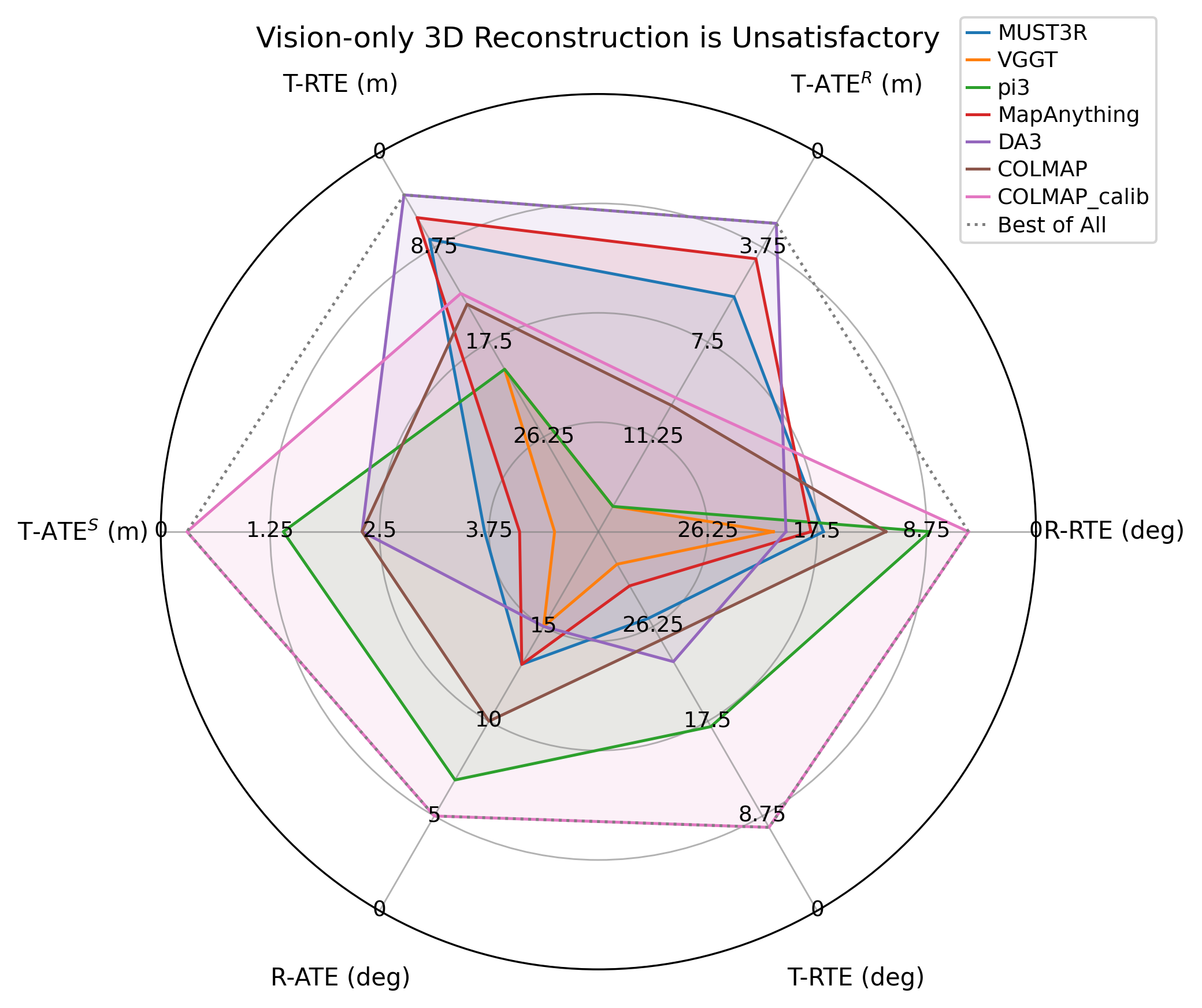








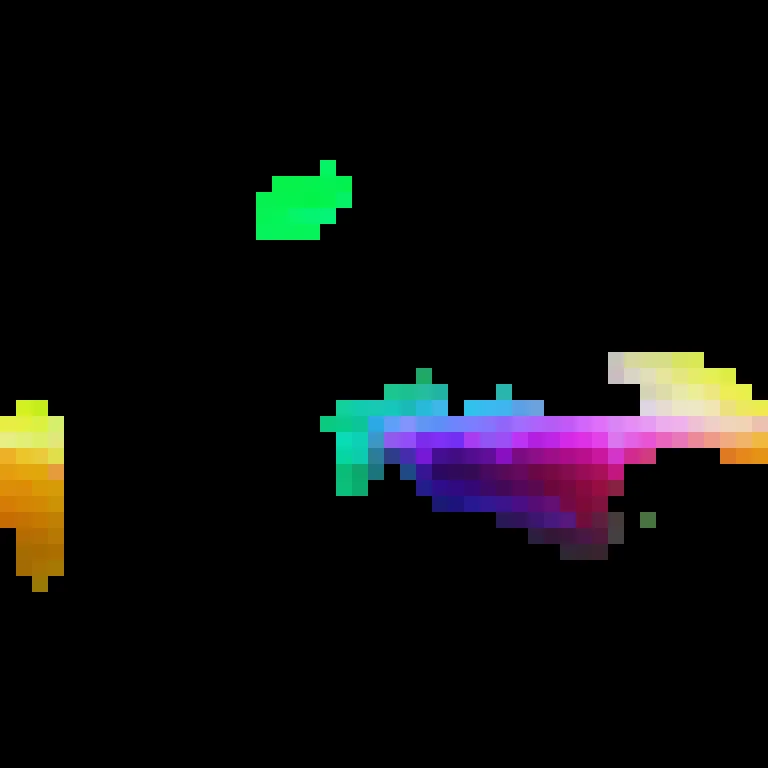
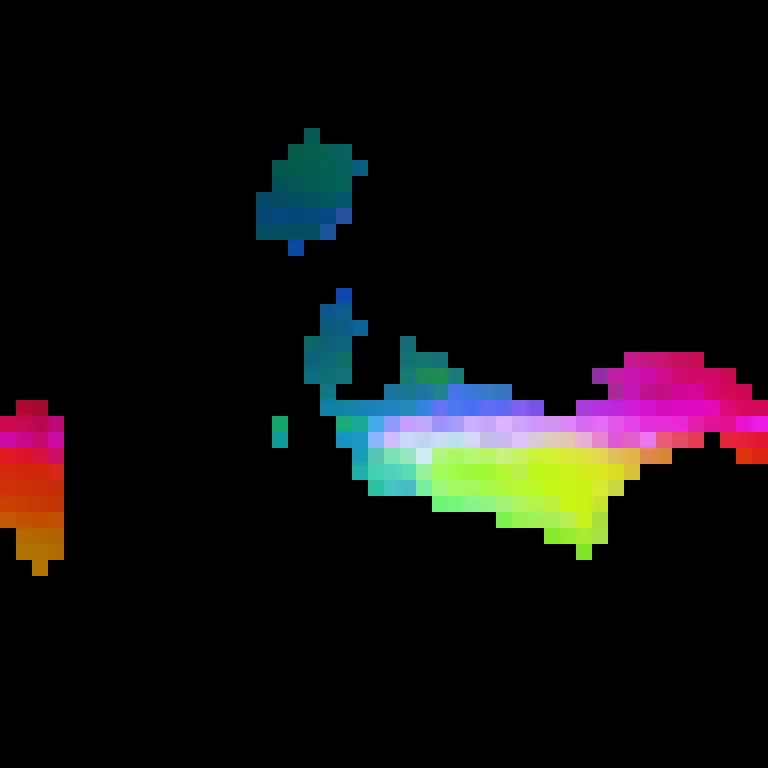
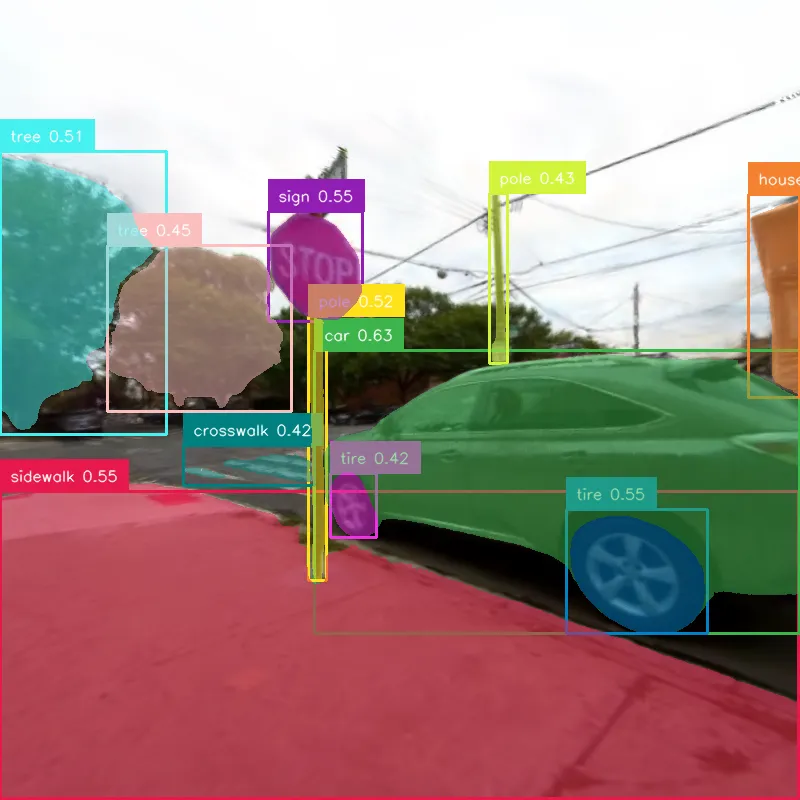
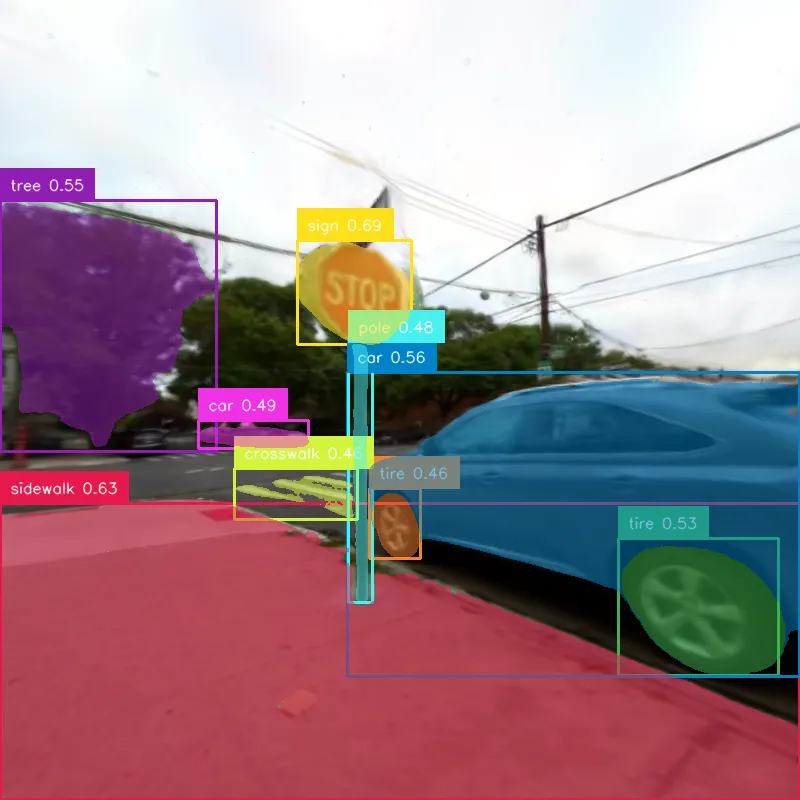


Multimodal Data Quality
Aligned multimodal signals, reconstruction quality, and lighting variation across captured scenes.
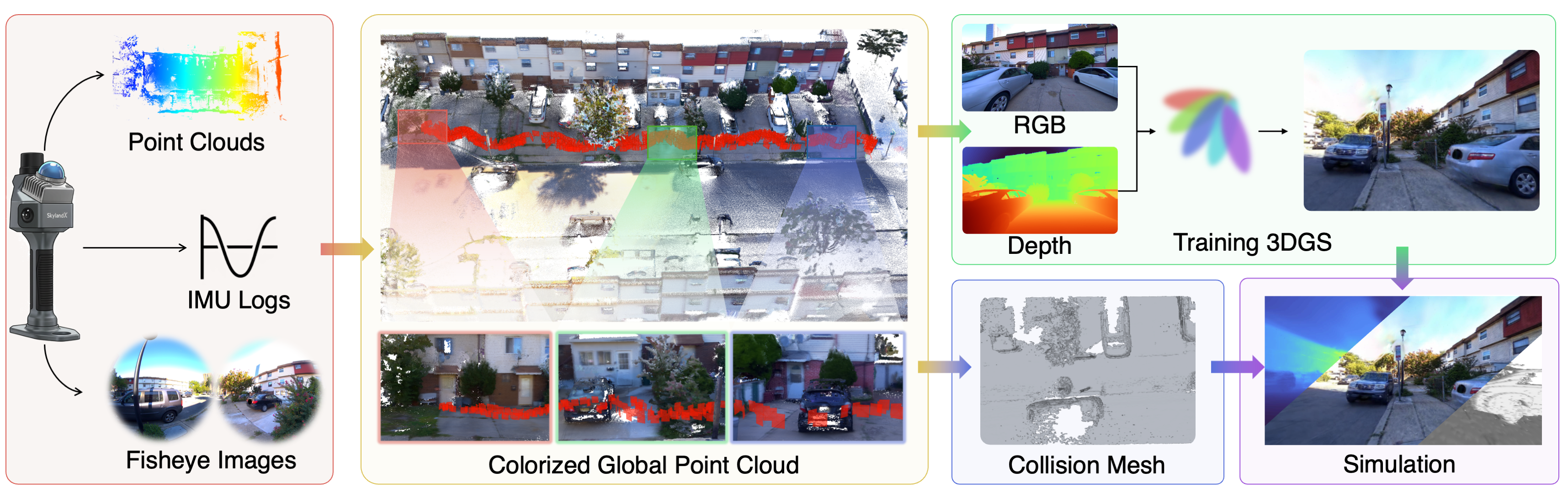
Wanderland captures large-scale indoor, outdoor, and mixed lighting scenes with metrically aligned geometry. These synchronized fly-throughs highlight the dataset's visual diversity, coverage scale, and embodied evaluation setup.
Aligned multimodal signals, reconstruction quality, and lighting variation across captured scenes.
Large and non-overlapping trajectories that stress open-world coverage.
Unity walkthroughs with metric mesh collision and photorealistic 3DGS rendering.
Language, image-goal, and point-goal task examples for embodied evaluation.
The work was supported in part through NSF grants 2514030, 2238968, and 2345139, in part by NVIDIA Academic Grant Program, and the NYU IT High Performance Computing resources, services, and staff expertise. We thank SkylandX for their technical support. We thank Hellon Luo, Shiqi Wang, Ying Wang, Zhicheng Yang, and Yining Zheng for their help in data collection. We thank Juexiao Zhang and Sihang Li for insightful discussion.
@inproceedings{liu2026wanderland,
title={Wanderland: Geometrically Grounded Simulation for Open-World Embodied AI},
author={Liu, Xinhao and Li, Jiaqi and Deng, Youming and Chen, Ruxin and Zhang, Yingjia and Ma, Yifei and Guo, Li and Li, Yiming and Zhang, Jing and Feng, Chen},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1041--1052},
year={2026}
}