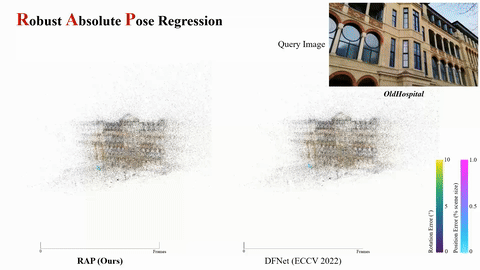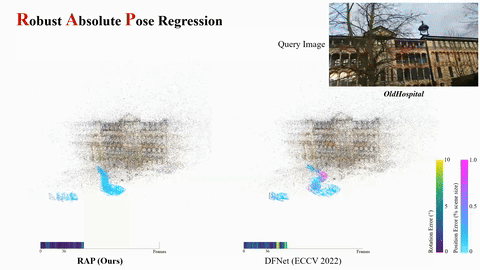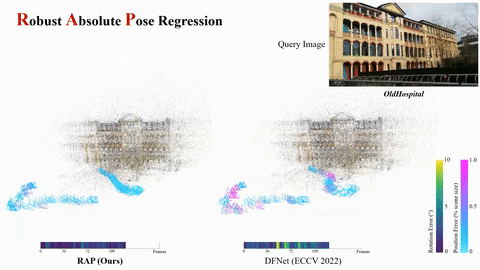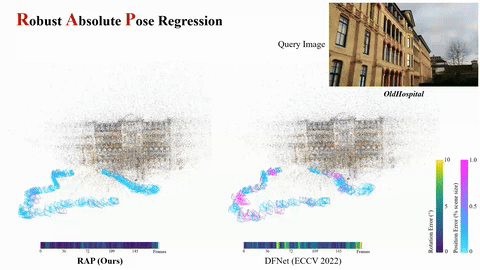
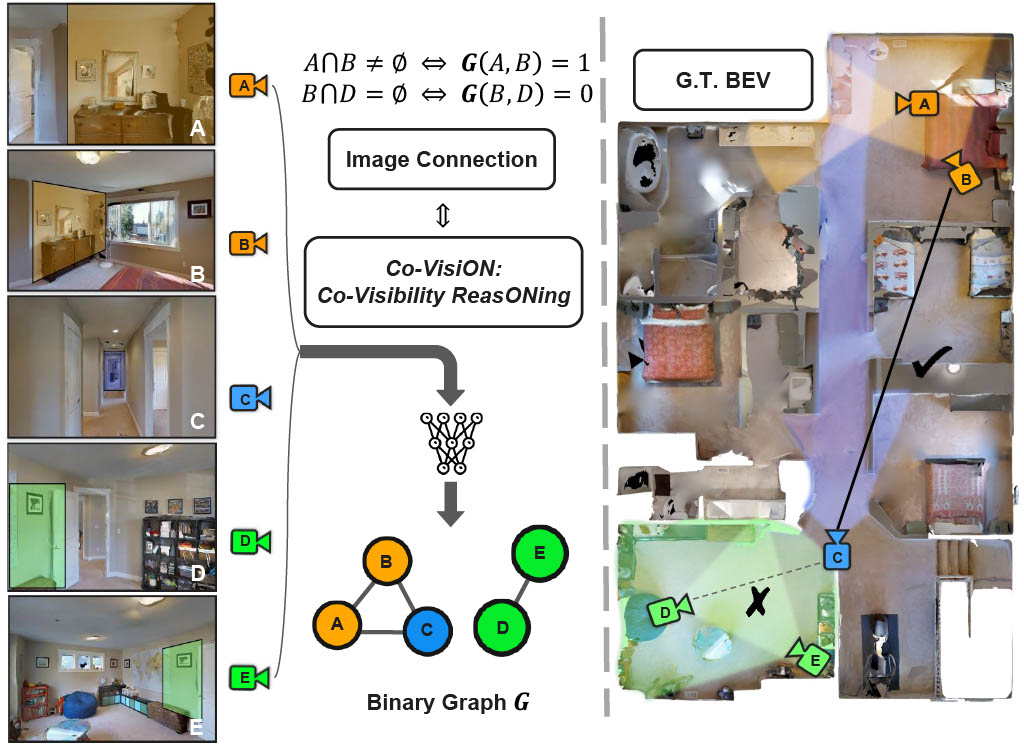
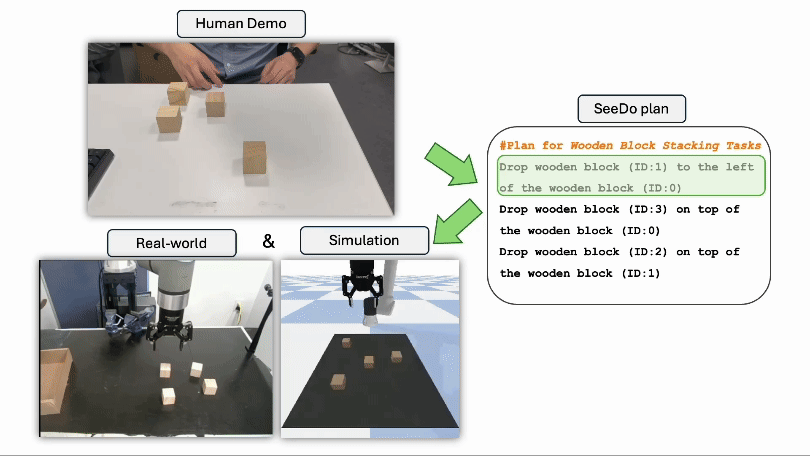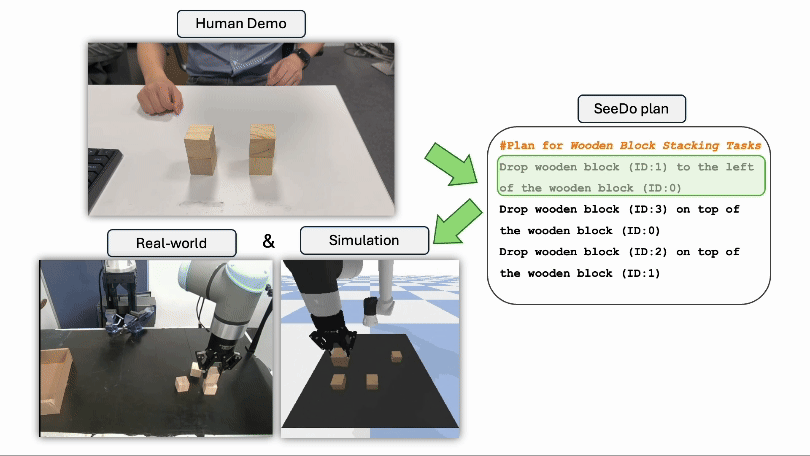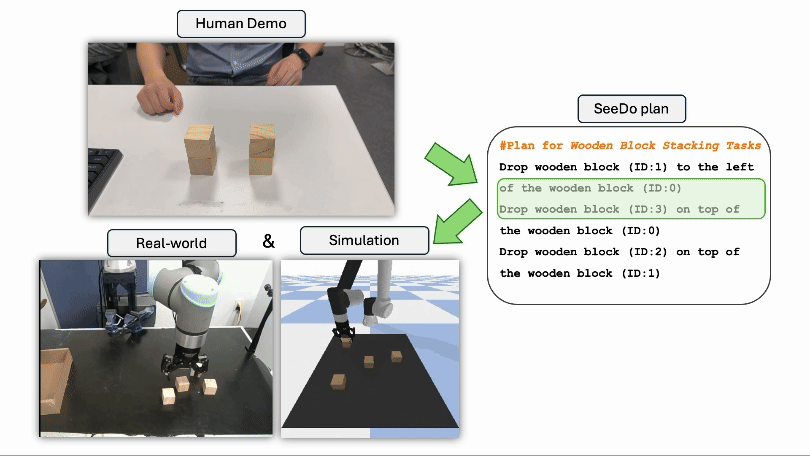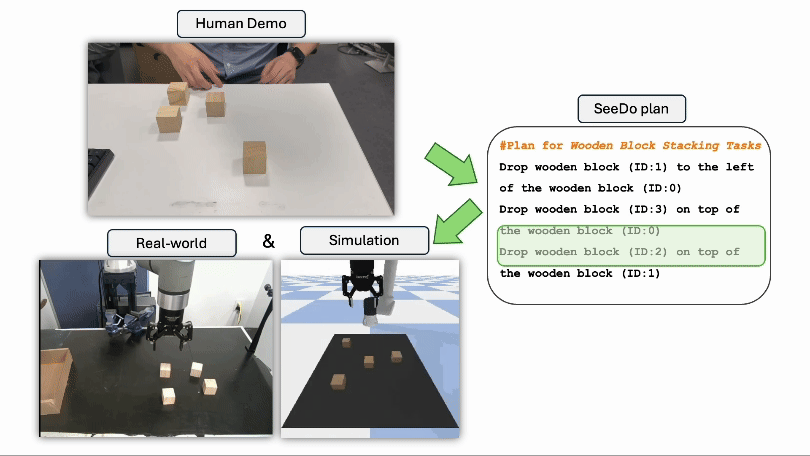
Jisang Han
Sunghwan Hong
Jaewoo Jung
Wooseok Jang
Honggyu An
Qianqian Wang
Seungryong Kim
Chen Feng
Heyang Yu
Yinan Han
Xiangyu Zhang
Baiqiao Yin
Bowen Chang
Xiangyu Han
Xinhao Liu
Jing Zhang
Marco Pavone
Saining Xie
Yiming Li
Jiaqi Li
Youming Deng
Ruxin Chen
Yingjia Zhang
Yifei Ma
Li Guo
Sihang Li
Siqi (Kevin) Tan
Zhen Jia
Boyi Li
Yan Wang
Boris Ivanovic
Yurong You
Lingjie Liu
Yue Wang
Zeyu Jiang
Grace Chen
Chenyang Xu
Xue Wang
Irving Fang
Kristof Zyskowski
Shannon P. McPherron
Radu Iovita
Chao Chen
Nobel Dang
Juexiao Zhang
Wenkai Sun
Pengfei Zheng
Xuhang He
Yimeng Ye
Taarun Srinivas
Beichen Wang*
Juexiao Zhang*
Shuwen Dong
Taiyi Pan
Junyang He
Zegang Cheng (Hooley)
Li Ding
Ruoyu Wang