Overview and Baseline
Overview
 EgoPAT3D is a comprehensive dataset created and maintained by the AI4CE group at the New York University to enhance
action target location prediction during human manipulation tasks.
EgoPAT3D is a comprehensive dataset created and maintained by the AI4CE group at the New York University to enhance
action target location prediction during human manipulation tasks.
In recent years, egocentric datasets have been created to address three types of tasks: (1) Action Anticipation (2) Region Prediction (3) Trajectory Prediction. Meanwhile, the aforementioned datasets were created mainly for 2D, with only a few were created in 3D. With this in mind, Prediction of Action Target in 3D (PAT3D) is a special case of trajectory prediction, considering it is usually hard to predict trajectories when human hands remain mostly out of scope in egocentric views during manipulation tasks.Therefore, we limit our focus to predicting the endpoints (target) for human manipulation tasks, with a goal to compensate for action latencies and support timely reactions in human-robotics interactions.
To that end, our dataset contains 15 scenes, and each scene contains
(1) 10 RGB-D (visual)/IMU (motion) recordings
(2) 1 point cloud of the scene.
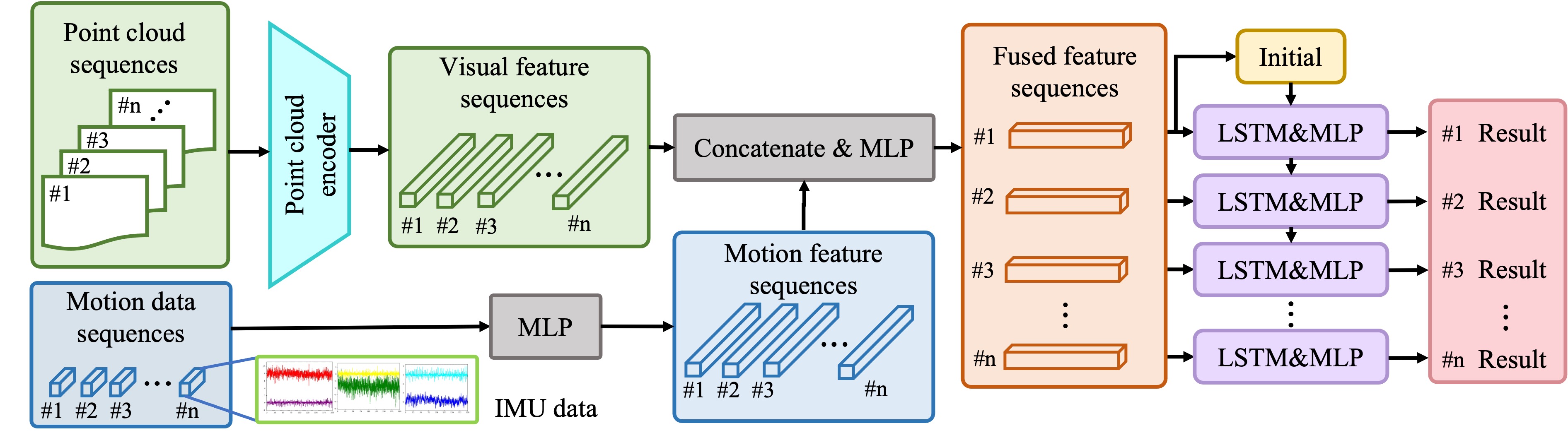
Along with the dataset, we design a classification loss function by using the prediction confidence to weigh the classification importance. i.e. L = Σ wt(yt - ȳt)2 In addition, we propose a baseline model, where the visual information and the motion information are extracted separately by two MLP’s before being concatenated and passed to another RNN-based prediction module (LSTM) for 3D target localization.
Overall, our main contributions are:
(1) We initiate the first study of egocentric target prediction in 3D.
(2) We build a novel dataset as well as evaluation metrics.
(3) We propose a baseline model for continuous prediction of action target.
Baseline Model
Our baseline model requires a real-time prediction based one varying-length historical information. We divide each
recording into clips of length T. Within each clip, prediction will be performed T times, each considering various
historical information. Specifically, we start by generating the ground truth for each clip following the procedures -
(1) Hand detection
(2) Hand center estimation
(3) Visual odometry calculation
(4) Hand location transformation of the target based on the
last frame within the clip.
After this, we extract visual and motion information separately from two MLP’s before
concatenating them. Lastly, we pass the fused feature set to another RNN-based prediction module (LSTM). Together with
the redesigned loss function, our goal is to (1) get prediction to be as close as possible to the ground truth (2) get
prediction as early as possible. Our baseline model is summarized in the flowchart as follows.