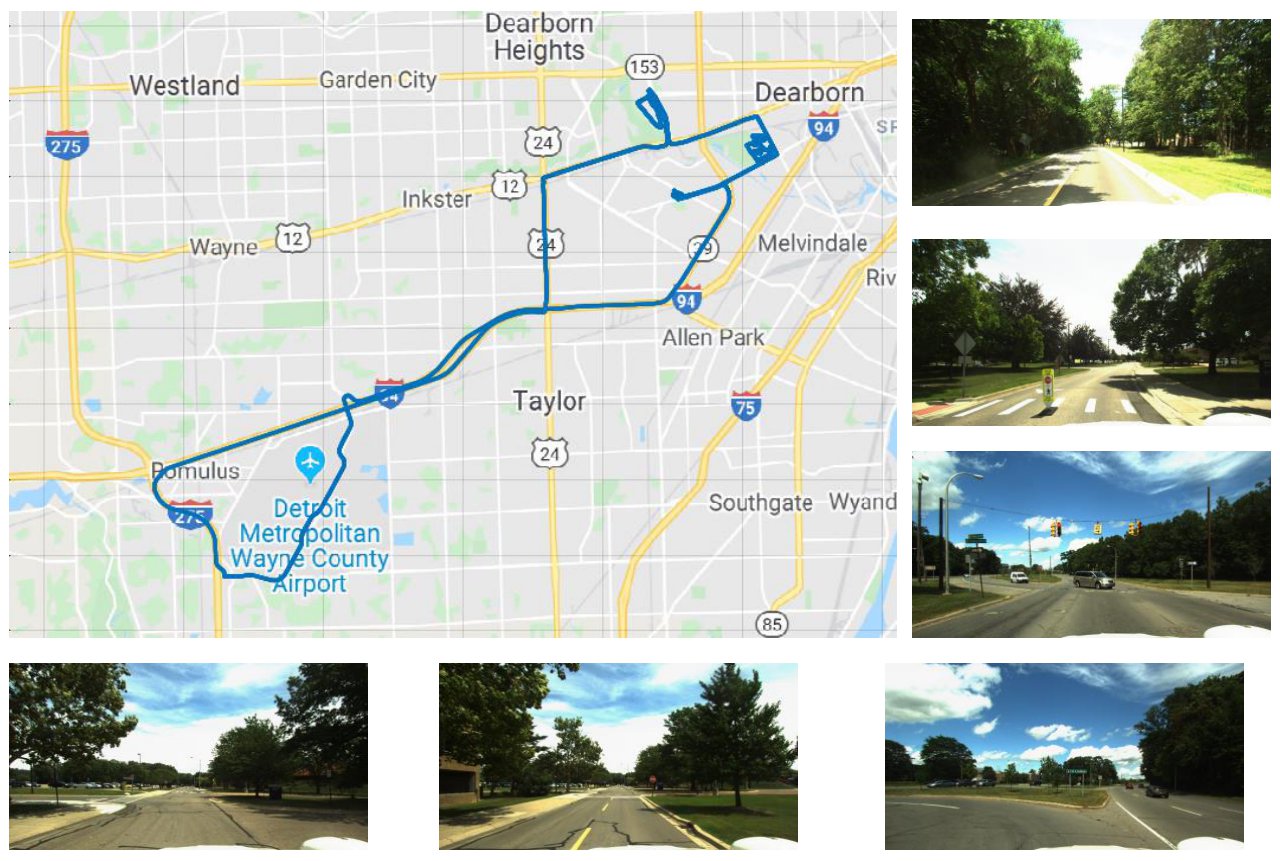

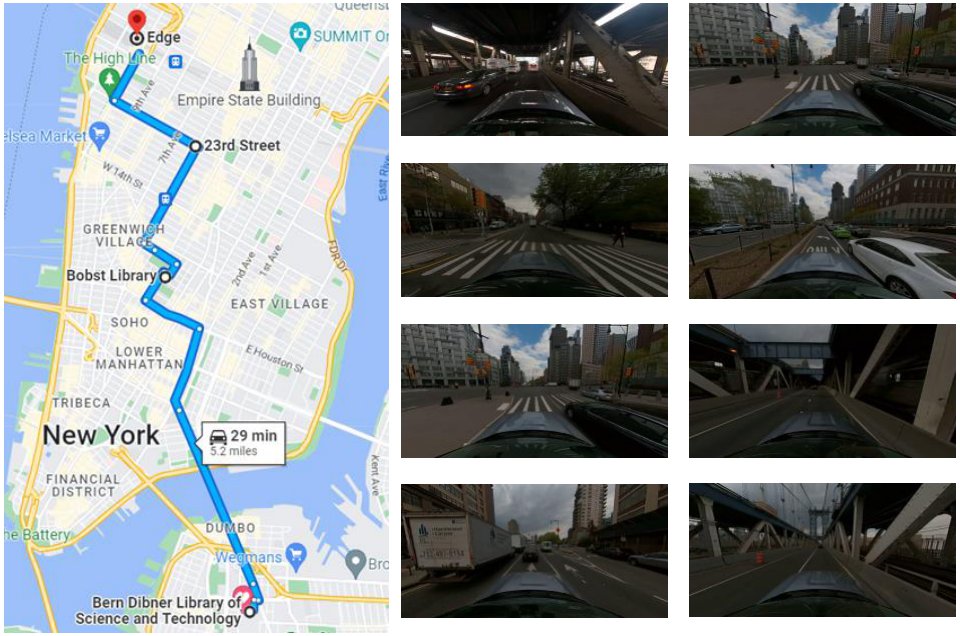
(a) Ford multi-AV Data
(b) Gibson multi-robot Data
(c) NYC MV Data
We evaluate our method using NetVLAD on three datasets: the Ford multi-AV Dataset, the NYC MV dataset, and the Gibson multi-robot dataset.
Ford multi-AV dataset: This dataset comprises outdoor scenes in rural Michigan. Evaluation includes both front and right-side views. We use 480 queries from residential scenes for training and 430 queries from university and vegetation scenes for testing. The maximum distance between the ego agent and collaborators is 5 meters.
NYC MV dataset: Captured in New York City, this dataset consists of images from the dense urban environment. The train-test split is based on GPS information to ensure disjoint locations. We use 207 queries for training and 140 for testing. The maximum distance between the ego agent and collaborators is 10 meters.
Gibson dataset: The Gibson multi-robot dataset contains indoor scenes simulated with Habitat-sim. We selected 350 queries for training and 279 queries for testing with front views. The training set and the test set do not share the same room, and the maximum distance between the ego agent and collaborators is 1 meter.

Video visualization of NYC MV data.

Video visualization of Ford multi-AV data.

Video visualization of Gibson multi-robot data.

Qualitative visual place recognition results on outdoor scenes. Correct retrievals are in green, and incorrect ones are in red. The first two rows are from Ford multi-AV data and the last two rows are from NYC MV data.

Qualitative visual place recognition results on the indoor scene (Gibson multi-robot data). Correct retrievals are in green, and incorrect ones are in red.

Fail cases in CoVPR. CoVPR can fail due to rotations and translations between ego agent and collaborators, especially in large rotations.
@article{li2023collaborative,
title={Collaborative Visual Place Recognition},
author={Li, Yiming and Lyu, Zonglin and Lu, Mingxuan and Chen, Chao and Milford, Michael and Feng, Chen},
journal={arXiv preprint arXiv:2310.05541},
year={2023}
}