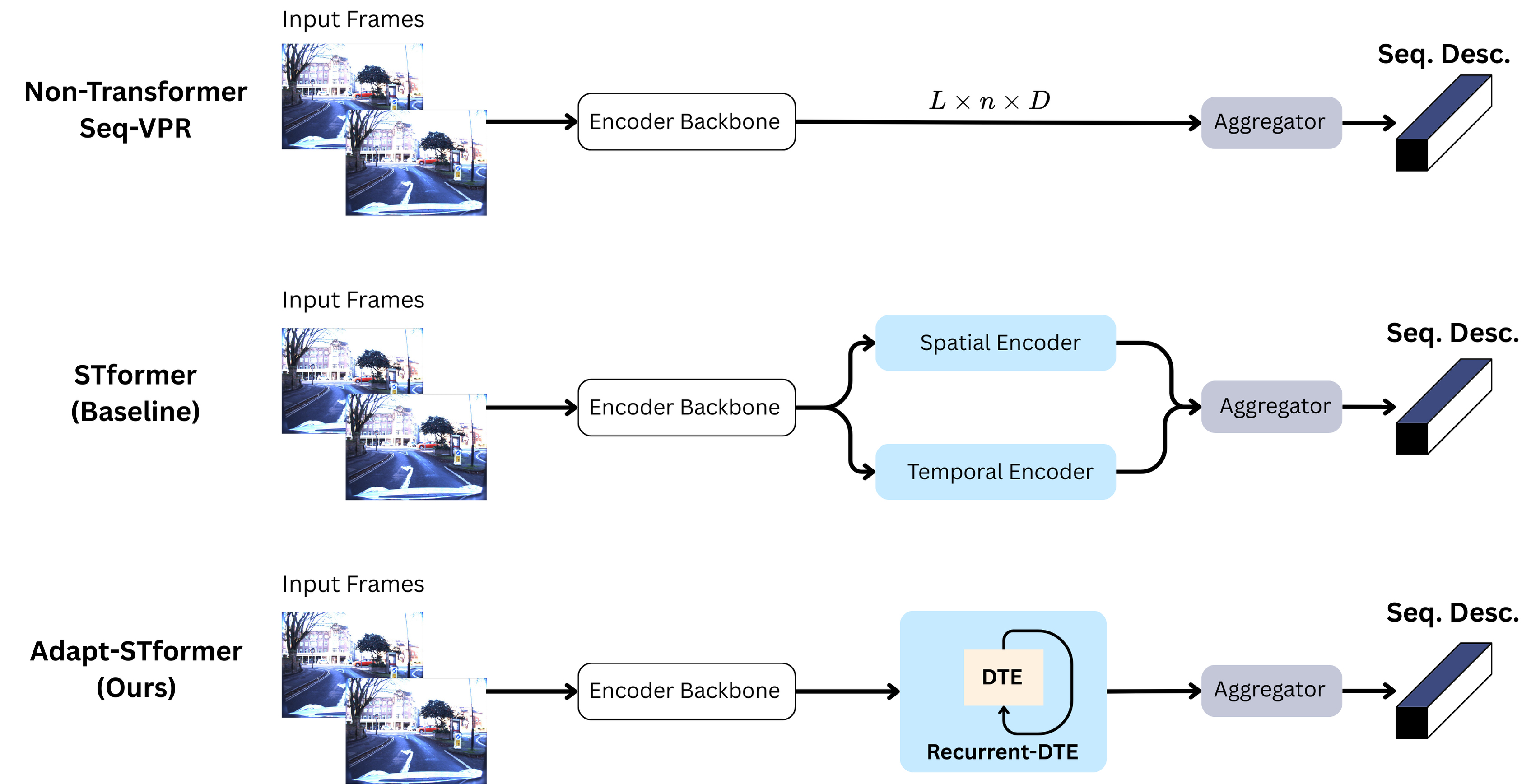
Adapt-STFormer's Recurrent-DTE module considers previous image features as latent states along with the current image, accounting for the temporal relationship across image sequences with variable length. This unifies the modeling of spatio-temporal relationships across images in one module
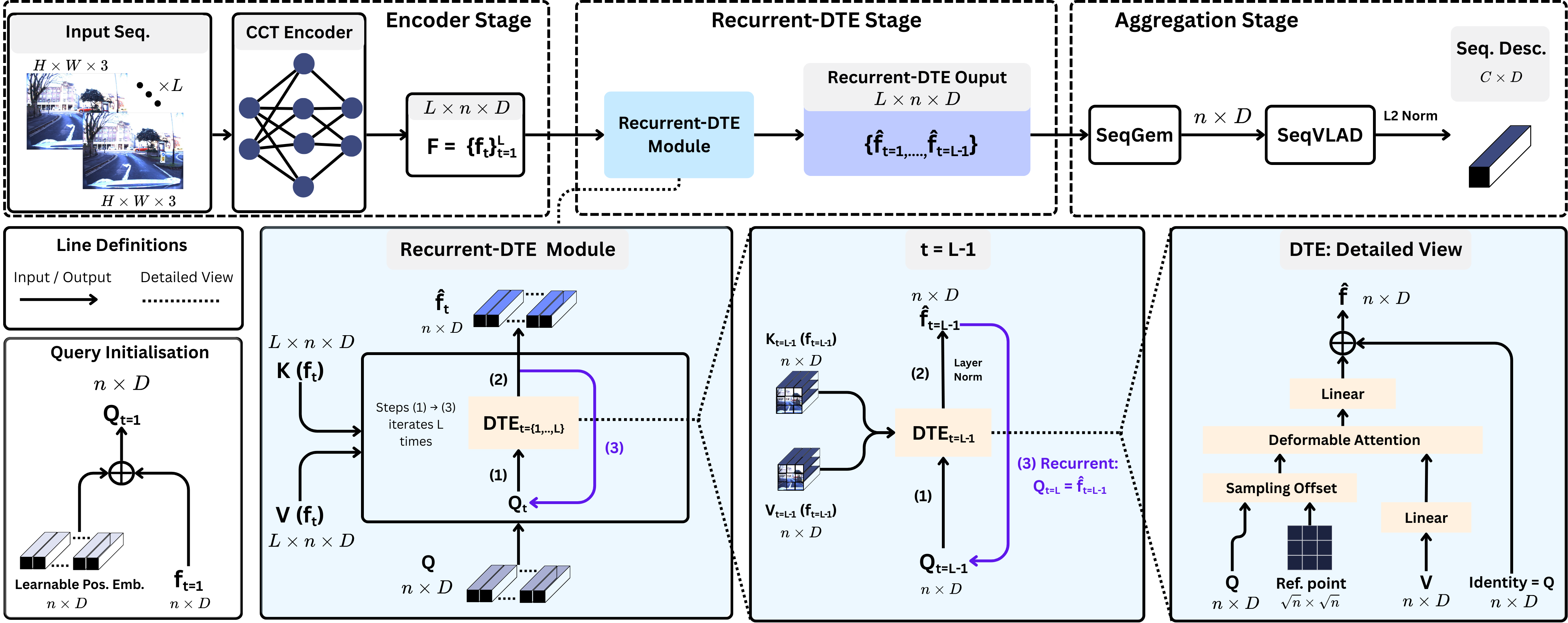
1. Image Encoding: For each image in the input sequence, we use CCT384 to obtain a set of image tokens. This effectively precomputes the inputs to the Recurrent-DTE module.
2. Recurrence: Given a new image, the DTE treats its CCT tokens as both key and value inputs, while the DTE outputs from the previous image serves as the query for the current iteration. For initialization, a learnable positional embedding is added to the first image's tokens to become the DTE query.
3. Aggregation: We concatenate the DTE outputs for each image along the batch dimension and apply the learnable mean pooling SeqGeM to flatten across the batch dimension. This result is fed to SeqVLAD for aggregation into the final descriptor.
Coming Soon