Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of the related approaches require a training set with ground truth sensor poses to obtain the positive and negative samples of each observation's spatial neighborhoods.
When such knowledge is unknown, the temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervision, although with suboptimal performance.
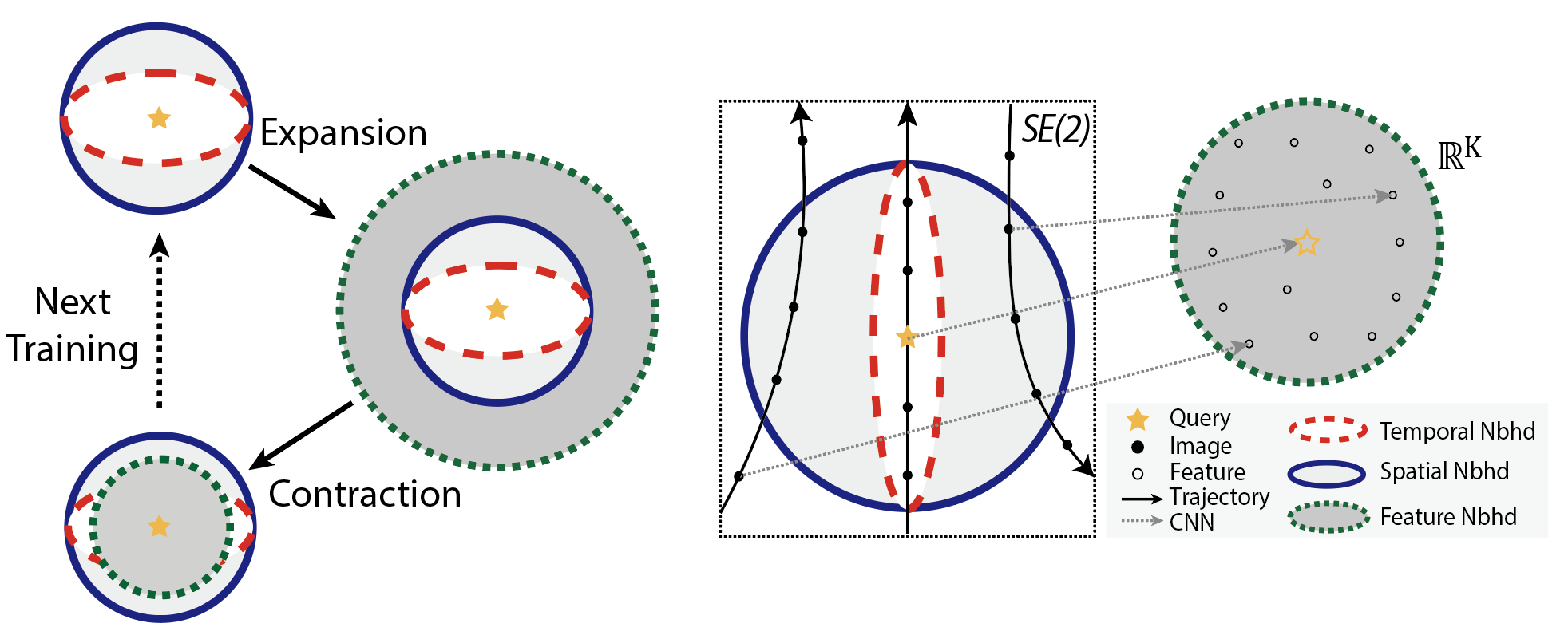
Inspired by noisy label learning, we propose a novel self-supervised VPR framework that uses both the temporal neighborhoods and the learnable feature neighborhoods to discover the unknown spatial neighborhoods.
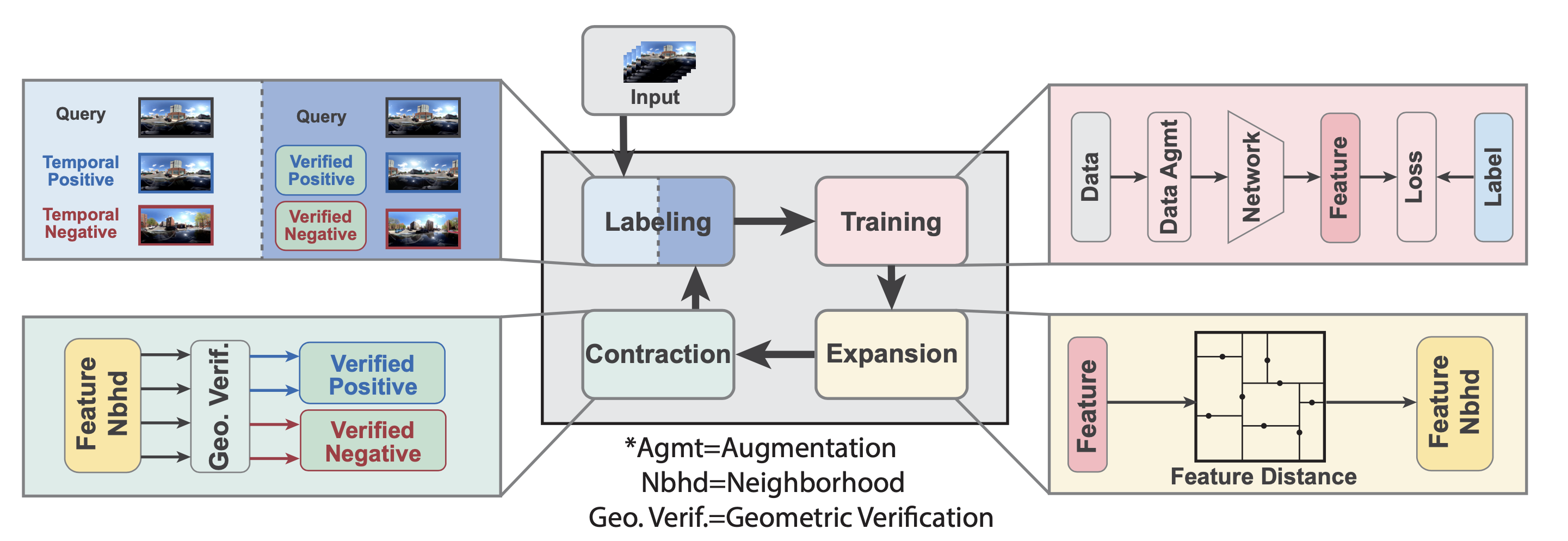
Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification.
We conduct comprehensive experiments on both simulated and real datasets, with input of both images and point clouds. The results demonstrate that our method outperforms the baselines in both recall rate, robustness, and a novel metric we proposed for VPR, the heading diversity.



(a) Point Cloud Data
(b) Habitat-sim Data
(c) NYU-VPR-360 Data
We test TF-VPR on three different kinds of environments: simulated 2D point clouds, simulated RGB images, and self-collected real-world RGB images. The codebase uses PyTorch framework with network parameters optimized using Adam. The learning rate is set as 0.001.
2D simulated point cloud dataset: we simulate 2D point clouds captured by the mobile agents equipped with virtual Lidar sensors. Specifically, we first create the 2D environment, represented as a binary image with the resolution of 1024 x 1024. The white and blue pixels correspond to the free space and the obstacles, respectively. Given the 2D environment, we interactively sample the trajectory of the mobile agent. For each sampled pose, the points in the simulated point clouds are the intersection points between laser beams and the obstacle boundaries. In our experiments, the virtual Lidar sensor has the field-of-view of 360° with the angular resolution of 1° (equivalently, each point cloud has 256 points). We created 18 trajectories sampled from 10 environments. Each trajectory contains 2048 poses. On average, the rotational and translation perturbation between two consecutive poses are ± 10° and ± 9.60 pixel, respectively.
Habitat-Sim RGB dataset: We collected the photo-realistic simulated images in the habitat-sim simulator using the Gibson dataset. The RGB images were captured by a virtual 360 camera mounted on a virtual robot in the environment. The robot moved according to the random exploration strategy. In total, we collected more than 10k images in 18 scenes.
NYU-VPR-360 dataset: We collected the real RGB dataset called NYU-VPR-360 captured by Gopro MAX, a dual-lens 360 camera with GPS recording. The GoPro camera was mounted on the top of the driving vehicle. Our dataset collection area selected an urban zone containing eight townhouse blocks. In total, we collected two different trajectories from the same start points. All trajectories contain visits to the same intersections for the loop closure detection. We designed three different actions for the same intersection: turn left, turn right and go ahead, with two opposite driving directions. Except for a few intersections due to traffic reasons, most intersections contain at least two kinds of actions with different driving directions.




Qualitative visual place recognition results on three different datasets. The first row shows the results of SPTM and the second row shows the results of TF-VPR. The first column is the query point cloud and column from 2nd row are the top N retrievals. green indicates true positives and red indicates false positives.}
@article{Chen2022arxiv,
author = {Chen, Chao and Liu, Xinhao and Xu, Xuchu and Li, Yiming and Ding, Li and Wang, Ruoyu and Feng, Chen},
title = {Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods},
journal = {arXiv:2208.09315},
year = {2022}
}