Introduction
Our dataset is named NYU-VPR. It is composed of images recorded in Manhattan, New York from April 2016 to March 2017. The images were recorded by cameras installed on the front, back, and side parts of taxis with auto-exposure. The dataset contains both side-view images and front-view images. There are 100,500 side-view and 101,290 front-view images, each with a 640x480 resolution. On the basis of raw images, we use MSeg, a semantic segmentation method, to replace moving objects such as people and cars with white pixels. Fig. 1 compares anonymized and raw images.

The images were recorded on streets around Washington Square Park. The trajectories of the locations where the images were recorded are shown in Fig. 2. Since the cameras were placed on fleet cars, and their routes were random, the frequencies of locations where the images were taken are different. The frequencies of the locations where the side-view and front-view images were recorded are shown in Fig. 3 and Fig. 4 respectively.
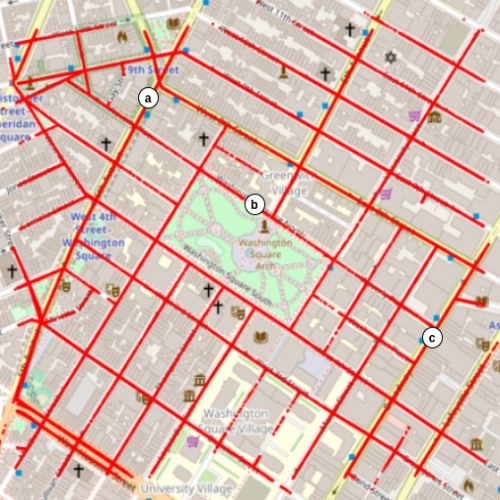
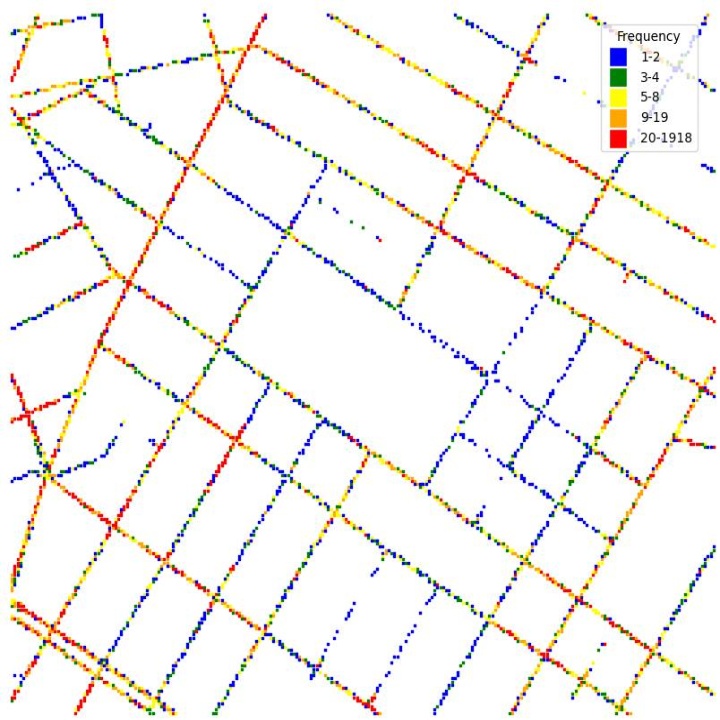
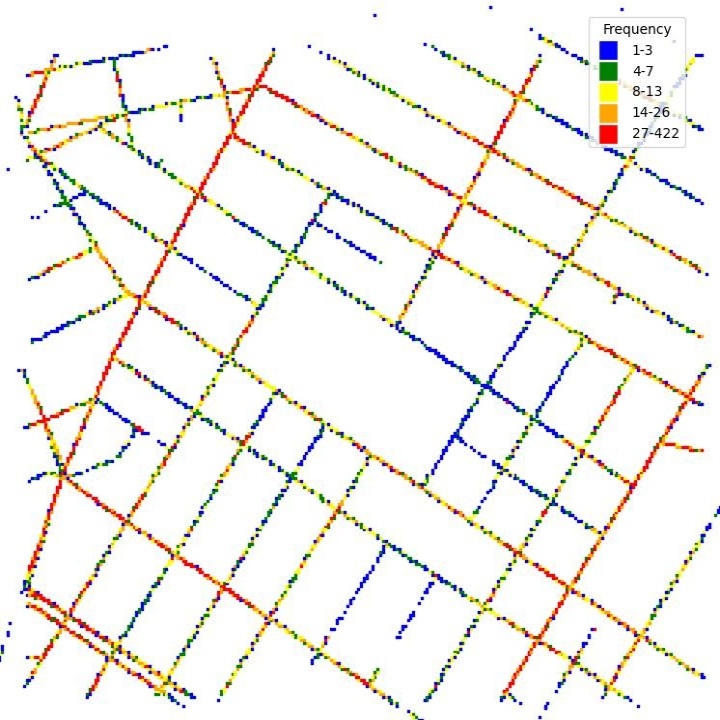
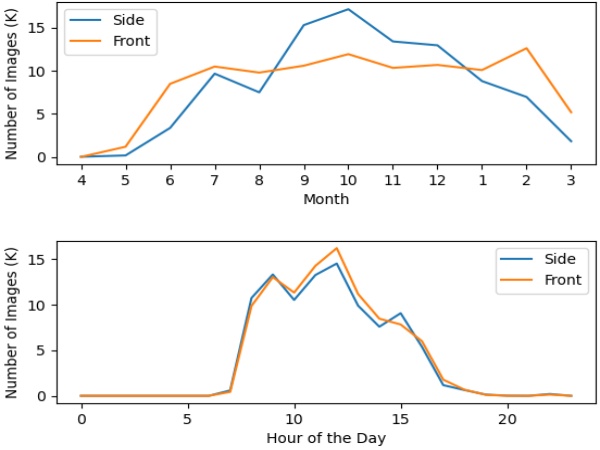
Fig. 5 shows the time distribution. Since it contains images captured from May 2016 to March 2017, our dataset includes all four seasons. Therefore, it contains various changes of weather, illumination, vegetation, and road construction. As shown in Fig. 6, we can see image changes at the same location as the season changes.