Deep Weakly Supervised Positioning for Indoor Mobile Robots
Abstract
PoseNet can map a photo to the position where it is taken, which is appealing in robotics. However, training PoseNet requires full supervision, where ground truth positions are non-trivial to obtain. Can we train PoseNet without knowing the ground truth positions for each observation? We show that this is possible via constraint-based weak-supervision, leading to the proposed framework: DeepGPS. Particularly, using wheel-encoder-estimated distances traveled by a robot along random straight line segments as constraints between PoseNet outputs, DeepGPS can achieve a relative positioning error of less than 2% for indoor robot positioning. Moreover, training DeepGPS can be done as auto-calibration with almost no human attendance, which is more attractive than its competing methods that typically require careful and expert-level manual calibration. We conduct various experiments on simulated and real datasets to demonstrate the general applicability, effectiveness, and accuracy of DeepGPS on indoor mobile robots and perform a comprehensive analysis of its robustness.
Results for PoseNet with noisy ground truth (use 9 scenes for now)
Since the original PoseNet uses the SFM result as the ground truth poses, in our photo-realistic simulation experiment, in addition to train the PoseNet using accurate ground truth positions, we also train it with noisy ground truth positions to simulate the noise introduced by the SFM. The noise follows 2D Gaussian distribution with a standard deviation of 1 cm.
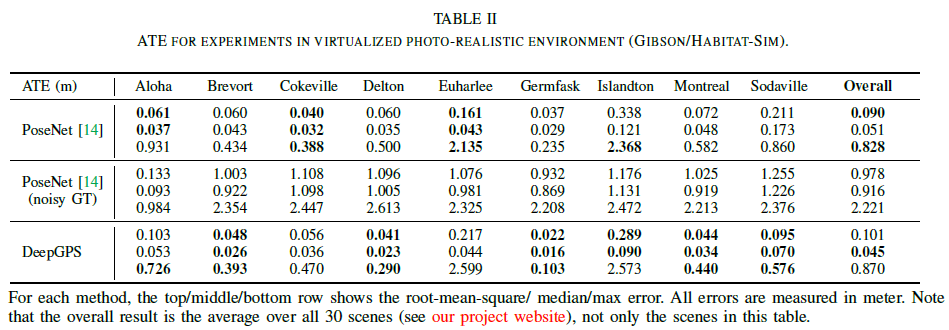
Results for photo-realistic environment experiment (all 30 scenes)
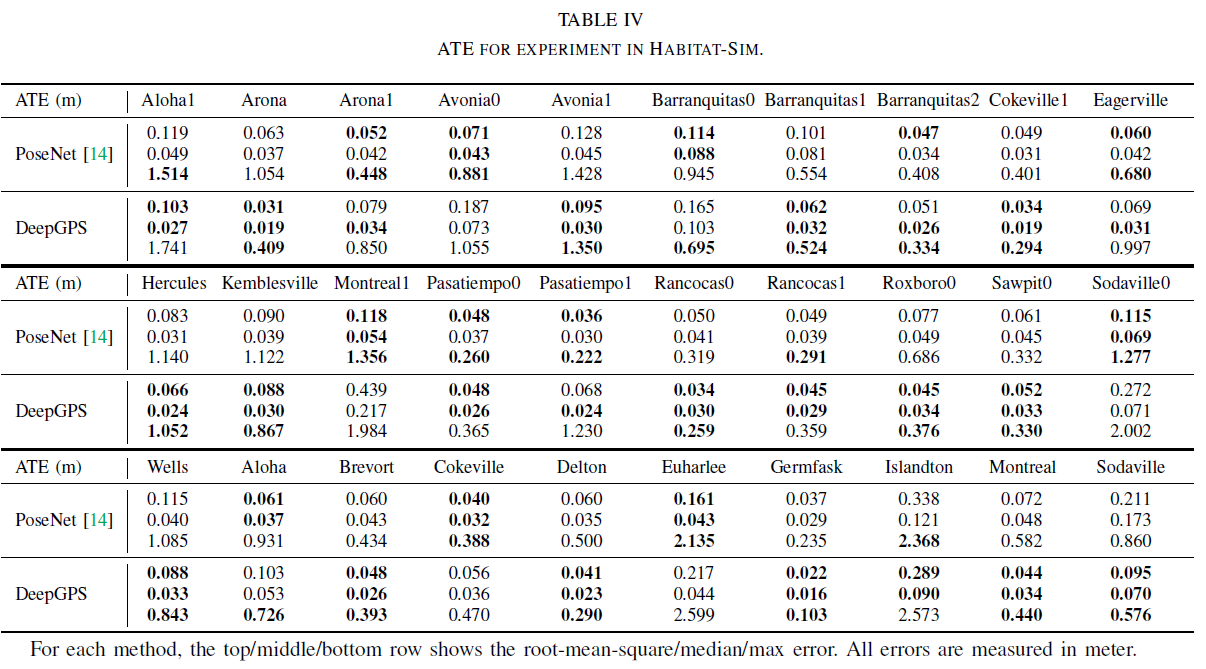
Experiment with a simulated 2D environment using Lidar
Experimental settings
We use the simulator in DeepMapping[14] to create four 2D environments and a virtual 2D Lidar scanner scans point clouds in these environments. Each local scan has 256 points which are arranged in order. We choose to use an MLP as . The number of neurons in each layer of
is 512, 512, 512, 1024, 512, 512, 256, 256, 128, 2 respectively. The input layer is the flattened 2D coordinates of the point clouds.
is set to 10,000, and
is set to 100. In each training iteration, at each position, 5 observations are randomly selected from the 100 different orientations. The testing set used for quantitative evaluation has 2,000 samples.
Baseline method
We compare our methods with K-Nearest Neighbor (KNN), which finds the closest instance in the training set to the query observation and use the ground truth position attached to that instance as the estimated position. However, it is unfeasible to apply KNN on the raw observation space, due to the high dimension. Therefore, we apply Principle Component Analysis (PCA) to reduce the dimension from 512 to 128 before KNN.
Results
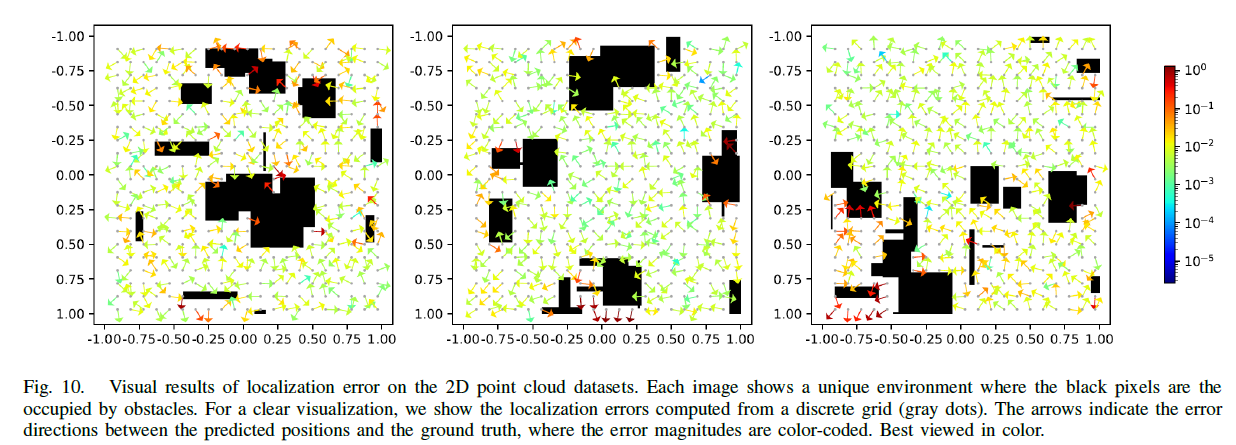
On the 2D Lidar point cloud dataset. Our method has better performance on median error and PCA+KNN method has better performance on RMSE and Max error (see Table V). This is because the positions in our training set have very large density and the PCA+KNN method can almost memorize each location in the environment. However, memory efficiency is very low for PCA+KNN. Our method only takes about 2 million float number of memory during operation while PCA+KNN takes about 66 million, which is 33 times of our method. Bedsides, the memory usage grows with the increasing size of training set. Again, our method does not need ground truth positions. Figure 10 illustrates the spatial distribution of the error. We found that the area that are surrounded by obstacles has the largest error. This is because that our method relies on the distances between locations. The obstacles surrounding an area limit the measurement of distance from many directions. Therefore, the constraints on the estimated positions in such an area are not strong enough, which makes estimation degenerated. One way to improve this is to apply techniques that can measure distance through obstacles, for instance, Wi-Fi. In this case, we can have many robots in the same environment. The distances between robots can be measured through obstacles, which provide more constraints on the position estimation in addition to the distances measured by wheel encoder.
Example images collected in Habitat-sim [50]

Example room layout in Habitat-sim [50]