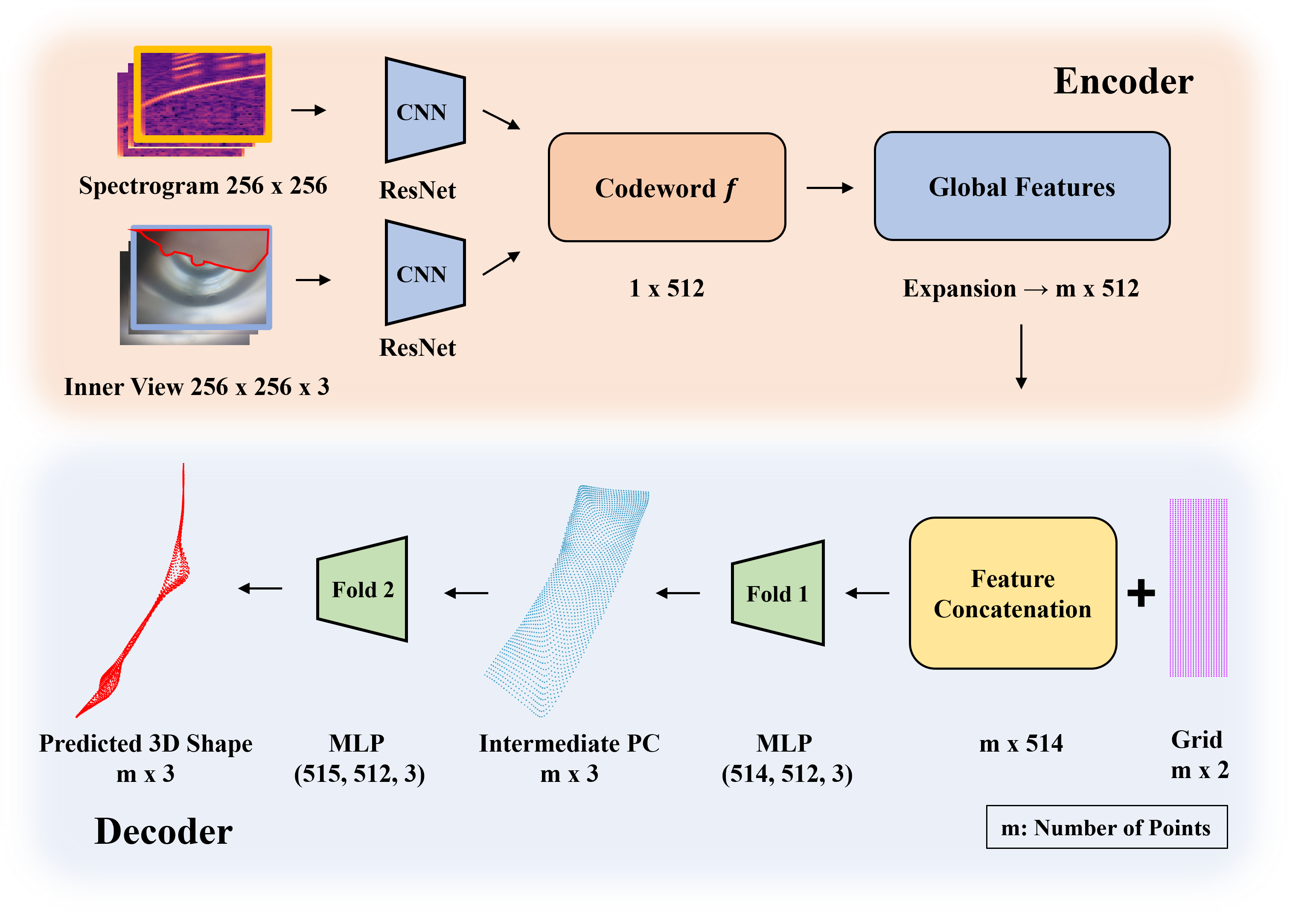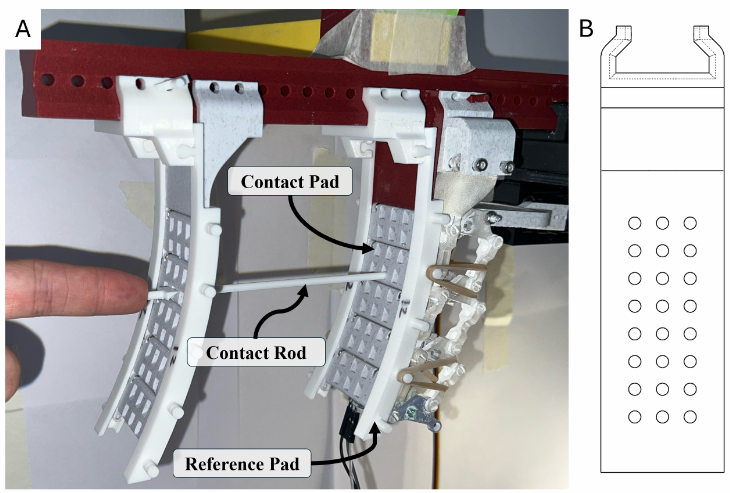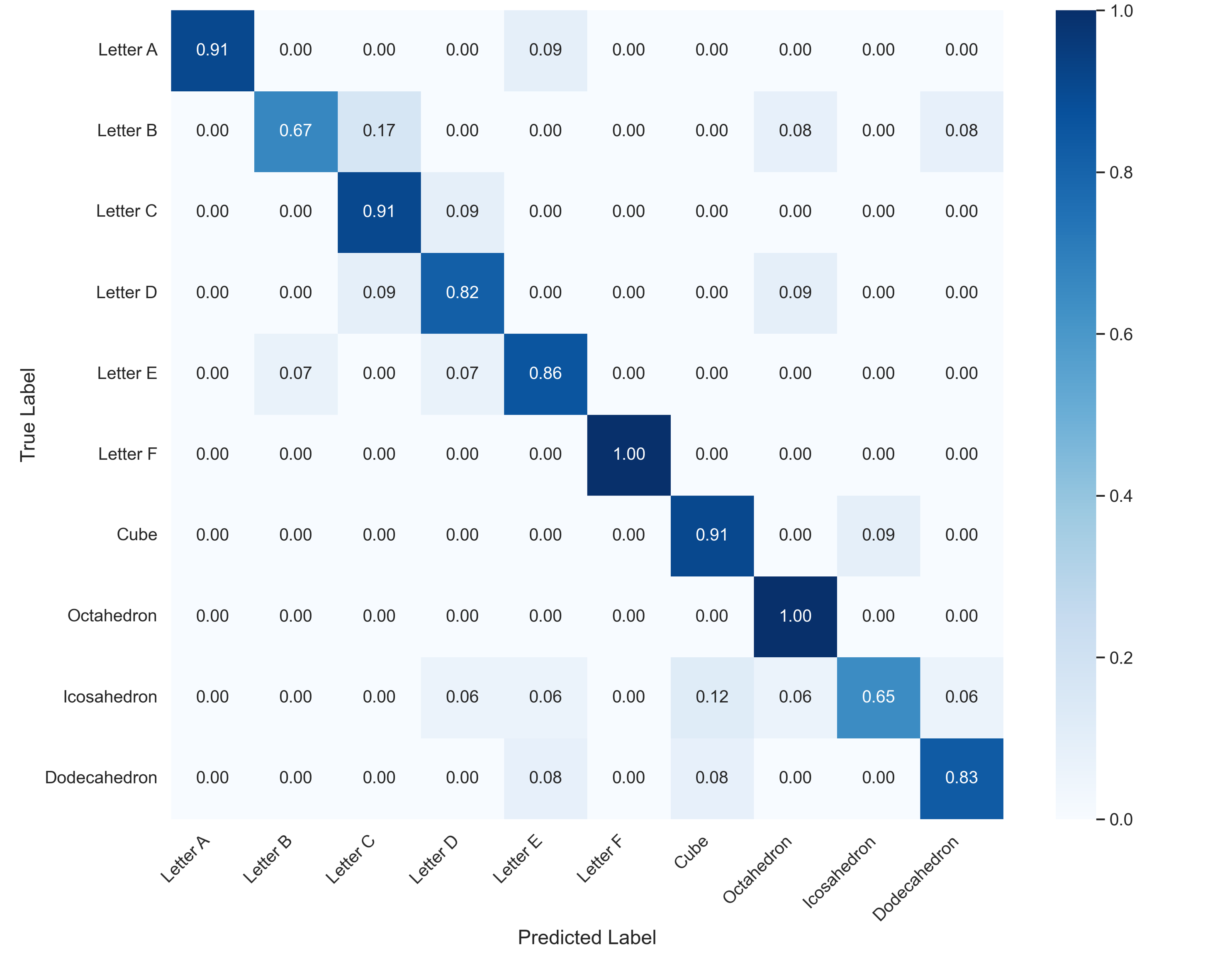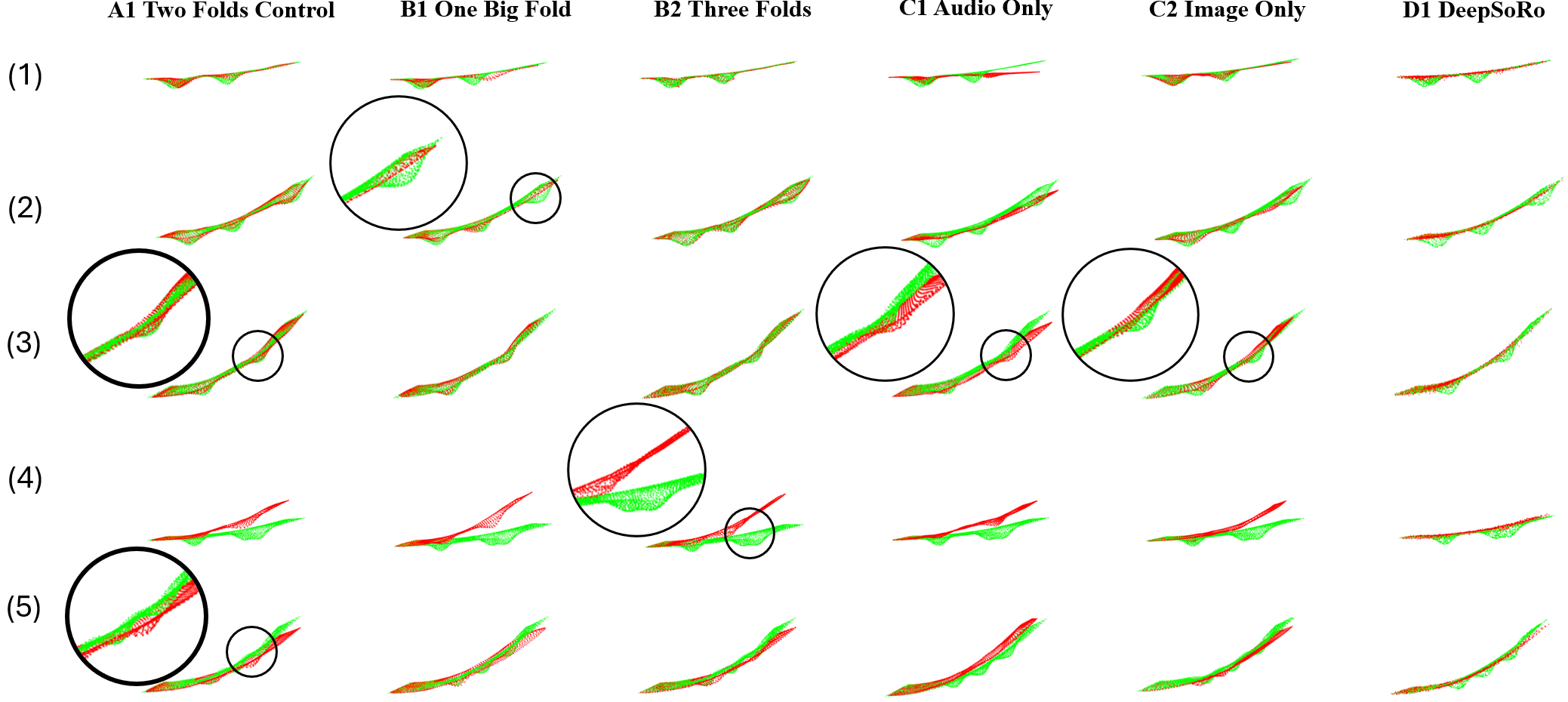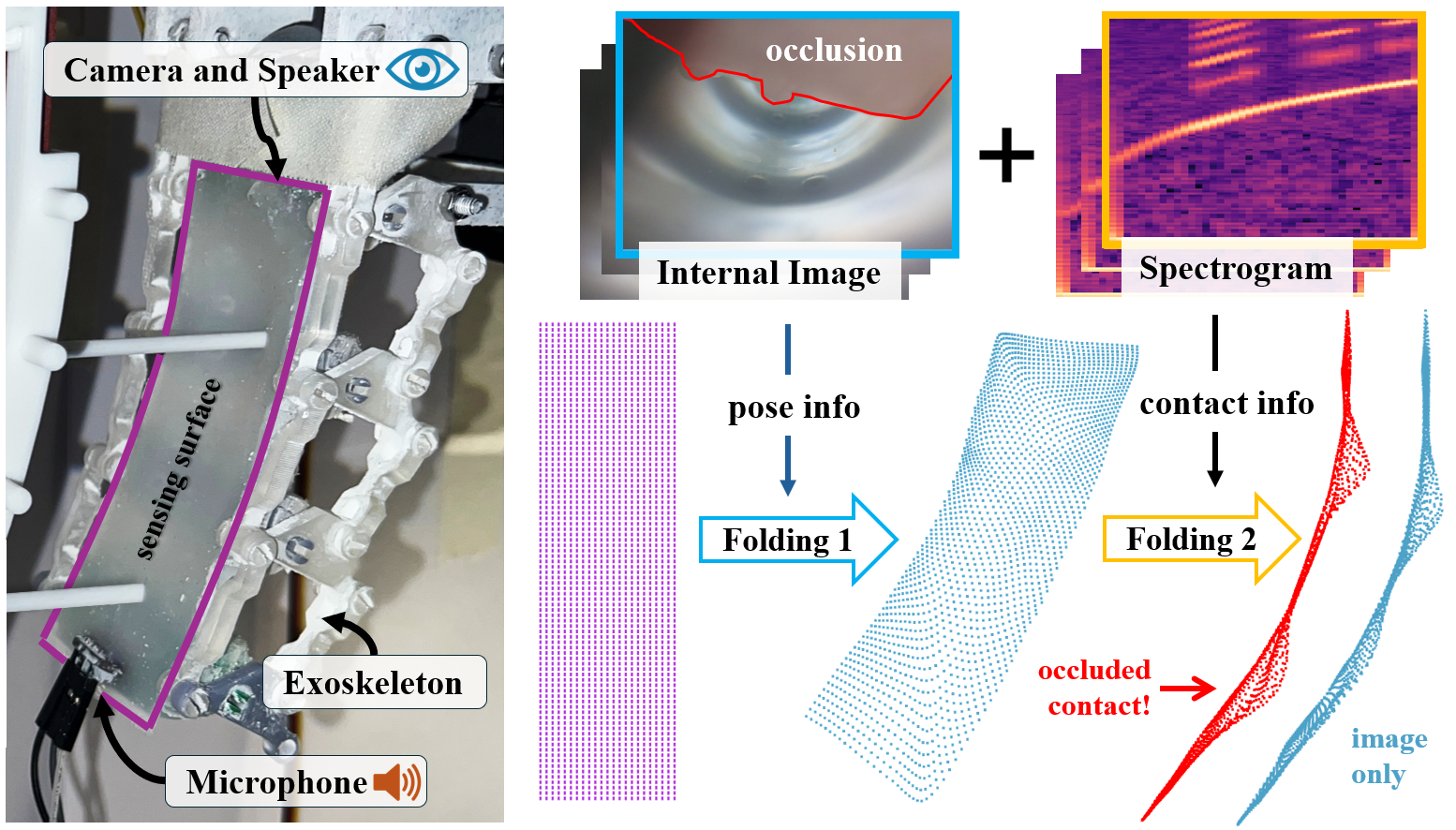
Overview of our multimodal proprioception framework. A soft robotic finger is instrumented with an internal camera, speaker, and microphone. The camera captures global bending, while spectrograms from acoustic reflections provide complementary contact cues, especially in occluded regions. The modalities are fused and processed through sequential folding modules: Folding 1 reconstructs the global pose, and Folding 2 refines the surface with localized contact deformations.